
Durch SAST (Static Application Security Testing) zu besserer Software
Sicherheit in der Softwareentwicklung ist kein optionales Feature – sie ist eine Grundvoraussetzung. Dennoch zeigt die Praxis immer wieder, dass Sicherheitslücken oft erst spät im Entwicklungsprozess oder sogar erst im laufenden Betrieb entdeckt werden. Zu diesem Zeitpunkt ist die Behebung nicht nur aufwändig, sondern auch teuer. Bereits in einem Report aus dem Jahr 2002 wird dokumentiert: Je später ein Fehler im Software Development Lifecycle gefunden wird, desto höher steigen die Kosten für seine Behebung – im schlimmsten Fall auf ein Vielfaches dessen, was eine frühe Korrektur gekostet hätte.
Genau hier setzt Static Application Security Testing – kurz SAST – an. SAST ermöglicht es Dir, Deinen Quellcode automatisiert auf Sicherheitslücken zu prüfen, noch bevor die Anwendung überhaupt ausgeführt wird. Damit verschiebt sich die Sicherheitsprüfung dorthin, wo sie den größten Mehrwert hat: direkt in den Entwicklungsprozess.
In diesem Beitrag bekommst Du einen strukturierten Überblick darüber, was SAST ist, wie es technisch funktioniert, welche Schwachstellen es erkennt – und wo seine Grenzen liegen. Außerdem zeigen wir Dir, wie Du SAST sinnvoll in Deinen Entwicklungsalltag integrieren kannst.
Dieser Beitrag richtet sich an Entwicklerinnen und Entwickler, die ihre Codequalität und Sicherheit gezielt verbessern möchten, sowie an Teamleads und Projektverantwortliche, die Sicherheitsprozesse strukturiert in ihren Entwicklungsworkflow einbinden wollen. Auch IT-Verantwortliche in Unternehmen, die erstmals mit dem Thema Anwendungssicherheit in Berührung kommen, finden hier einen praxisnahen Einstieg.
Was ist SAST? – Definition
Static Application Security Testing, kurz SAST, ist eine Methode zur automatisierten Sicherheitsanalyse von Software. Dabei wird der Quellcode, Bytecode oder Binärcode einer Anwendung auf Schwachstellen untersucht – ohne dass die Software dafür ausgeführt werden muss. Man spricht in diesem Zusammenhang auch vom sogenannten White-Box-Testing: Das Analyse-Tool hat vollständigen Einblick in den Code und bewertet dessen Struktur und Logik direkt.
SAST findet in der Regel bereits während der Entwicklungsphase statt und liefert Dir Hinweise auf sicherheitskritische Stellen direkt dort, wo sie entstehen – im Code selbst.
Was unterscheidet SAST von DAST und SCA?
SAST ist nicht das einzige Verfahren im Bereich Application Security Testing. Zwei weitere Methoden tauchen im Kontext häufig auf:
Was ist DAST (Dynamic Application Security Testing)?
DAST testet eine Anwendung im laufenden Betrieb – also von außen, ohne Blick in den Quellcode. DAST simuliert dabei das Verhalten eines Angreifers und zeichnet mögliche Angriffe auf die laufende Anwendung aus dieser Perspektive nach, indem es prüft, wie die Anwendung auf Eingaben reagiert. Im Unterschied zu SAST setzt DAST erst später im Entwicklungsprozess an, nämlich dann, wenn die Anwendung bereits deploybar ist.
Was ist SCA (Software Composition Analysis)?
SCA richtet den Fokus nicht auf selbst geschriebenen Code, sondern auf eingebundene Drittanbieter-Bibliotheken und Open-Source-Komponenten. SCA prüft, ob bekannte Sicherheitslücken (CVEs) in den verwendeten Abhängigkeiten vorhanden sind.
Kurz zusammengefasst: SAST analysiert den Code, den Du schreibst. DAST testet die laufende Anwendung von außen. SCA prüft die Abhängigkeiten, auf die Du dich stützt. In der Praxis ergänzen sich alle drei Verfahren und bilden gemeinsam eine solide Grundlage für eine ganzheitliche Sicherheitsstrategie. Du bist auf der Suche nach Experten die Dich im Bereich SAST unterstützen? Dann bist du bei uns genau richtig!
Wie funktioniert SAST?
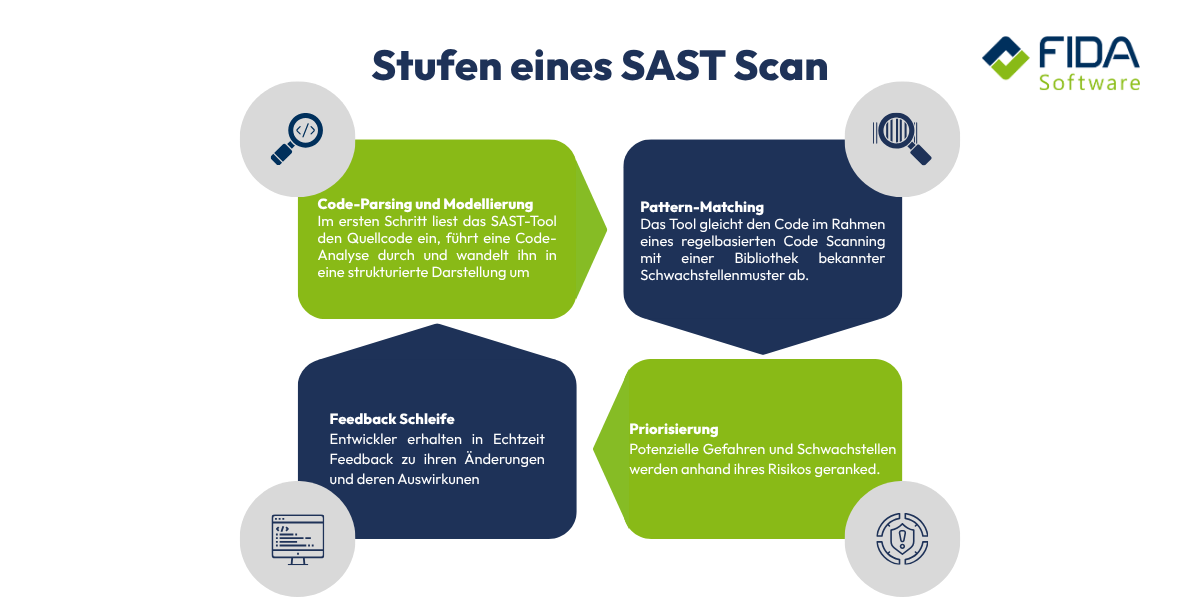
Damit SAST seinen Zweck erfüllen kann, läuft im Hintergrund ein mehrstufiger Analyseprozess ab. Dieser lässt sich vereinfacht in vier Schritte unterteilen:
Schritt 1: Code-Parsing und Modellierung
Im ersten Schritt liest das SAST-Tool den Quellcode ein, führt eine Code-Analyse durch und wandelt ihn in eine strukturierte Darstellung um – den sogenannten Abstract Syntax Tree (AST). Der AST ist eine Baumstruktur, die den logischen Aufbau des Codes abbildet: Welche Funktionen gibt es? Wie sind Variablen definiert? Wie hängen Komponenten miteinander zusammen? Diese Darstellung ermöglicht es dem Tool, den Code nicht nur als Text, sondern als strukturiertes Modell zu verstehen.
Schritt 2: Datenflussanalyse
Auf Basis des AST verfolgt das Tool in der Datenflussanalyse (Data Flow Analysis), wie Daten durch die Anwendung fließen – von ihrer Quelle bis zu ihrem Ziel. Dabei wird untersucht, welche Variablen welche Funktionen erreichen und ob dabei sicherheitskritische Stellen passiert werden, was die Erkennung unsicherer Datenpfade etwa bei SQL-Injection unterstützt.
Schritt 3: Taint-Analyse
Die Taint-Analyse ist eine Erweiterung der Datenflussanalyse. Dabei werden alle Daten, die aus nicht vertrauenswürdigen Quellen stammen – etwa Benutzereingaben aus einem Formular – als „verseucht" (englisch: tainted) markiert. Das Tool verfolgt diese Daten anschließend durch den gesamten Code. Landet ein solches Datenelement ungefiltert in einer sicherheitskritischen Funktion, zum Beispiel einer Datenbankabfrage, schlägt das Tool Alarm.
Schritt 4: Pattern-Matching und Regelanwendung
Parallel dazu gleicht das Tool den Code im Rahmen eines regelbasierten Code Scanning mit einer Bibliothek bekannter Schwachstellenmuster ab – etwa den OWASP Top 10. So werden gängige Fehlerbilder wie SQL-Injection oder Cross-Site Scripting zuverlässig erkannt.
Am Ende des Prozesses steht ein Bericht, der gefundene Schwachstellen nach Schweregrad klassifiziert, ihren genauen Ort im Code benennt, dabei oft die konkrete Codezeile markiert, die die Schwachstelle verursacht, und Hinweise zur Behebung liefert. Unsere Entwickler begleiten Dich in allen Schritten des SAST Prozesses
Wie kann SAST in den Entwicklungsprozess integriert werden?- Shift Left Security
Im klassischen Softwareentwicklungsprozess wurde Sicherheit häufig als letzter Schritt betrachtet – ein abschließendes Audit kurz vor dem Go-Live. Dieses Vorgehen hat einen entscheidenden Nachteil: Je später eine Schwachstelle entdeckt wird, desto aufwändiger und teurer ist ihre Behebung.
Das Prinzip Shift Left dreht diesen Ansatz um. „Nach links verschieben" bedeutet, Sicherheitsprüfungen so früh wie möglich im Software Development Lifecycle (SDLC) zu verankern – also bereits während des Schreibens von Code, nicht erst beim Testen oder Deploymentprozess. SAST ist dafür ein zentrales Werkzeug, da es Code analysieren kann, ohne dass die Anwendung ausgeführt werden muss – selbst unvollständiger Code lässt sich bereits scannen.
Integration in CI/CD-Pipelines
In der Praxis wird SAST direkt in die CI/CD-Pipeline und in DevSecOps-Pipelines eingebunden. Das bedeutet: Bei jedem Commit oder Pull Request wird automatisch ein Scan ausgeführt. Sicherheitsprobleme werden dabei als Echtzeit-Feedback unmittelbar nach Code-Updates zurückgemeldet, bevor neuer Code in den Hauptbranch einfließt. Zusätzlich lässt sich SAST als Plugin direkt in gängige Entwicklungsumgebungen (IDEs) integrieren, sodass Entwickler bereits beim Schreiben des Codes auf mögliche Schwachstellen hingewiesen werden und diese frühe Transparenz die Entwicklungsgeschwindigkeit unterstützt, ohne den Workflow stark auszubremsen.
Dieses Vorgehen stellt sicher, dass Sicherheit kein nachgelagerter Prozess bleibt, sondern ein fester Bestandteil des täglichen Entwicklungsworkflows wird.
Was erkennt SAST und was nicht?
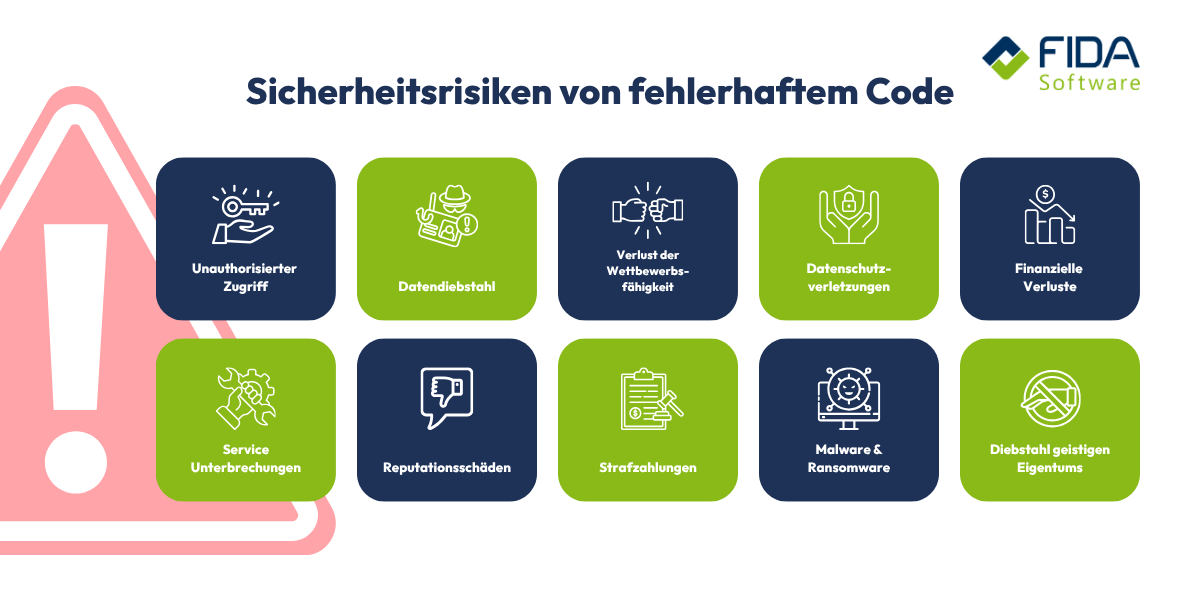
SAST ist ein leistungsfähiges Werkzeug, aber kein Allheilmittel. Um es sinnvoll einzusetzen, ist es wichtig zu wissen, wo seine Stärken liegen – und wo seine Grenzen.
Was SAST zuverlässig erkennt:
SAST ist besonders stark darin, Schwachstellen aufzudecken, die direkt im Code verankert sind. Dazu gehören typischerweise:
SQL-Injection: Benutzereingaben, die ungefiltert in Datenbankabfragen einfließen
Cross-Site Scripting (XSS): Nicht validierte Eingaben, die im Browser anderer Nutzer ausgeführt werden können
Pufferüberläufe: Fehlende Überprüfungen bei der Verarbeitung von Eingabedaten
Hardcodierte Zugangsdaten: Passwörter oder API-Keys, die direkt im Quellcode stehen
Unsichere Deserialisierung: Fehlerhafte Verarbeitung von serialisierten Daten
Pfad- und Befehlsinjektionen: Eingaben, die unkontrolliert in Dateisystem- oder Systemoperationen fließen
Im Wesentlichen deckt SAST den Großteil der OWASP Top 10 ab – also jene Schwachstellenkategorien, die in der Praxis am häufigsten auftreten und am gefährlichsten sind.
Wo SAST an seine Grenzen stößt
So hilfreich SAST ist, gibt es Bereiche, in denen es naturgemäß nicht weiterhelfen kann:
False Positives sind eines der bekannteren Probleme. Da SAST den Code statisch analysiert, ohne den tatsächlichen Ausführungskontext zu kennen, meldet es mitunter Schwachstellen, die in der Realität kein Risiko darstellen. Ohne sorgfältige Konfiguration und Nachbearbeitung kann das zu einem erheblichen Rauschen im Testergebnis führen. Bleiben echte Befunde dabei unbehandelt, können sie zudem Cyberangriffe begünstigen.
Laufzeitfehler bleiben für SAST unsichtbar. Fehler, die erst durch bestimmte Eingaben oder Systemzustände zur Laufzeit entstehen, lassen sich ohne Ausführung der Anwendung nicht erkennen – hier ist DAST das geeignetere Werkzeug.
Komplexe Geschäftslogik-Fehler entziehen sich ebenfalls der statischen Analyse. Ob eine Anwendung fachlich korrekt funktioniert oder ob eine Berechtigungslogik in einem konkreten Szenario versagt, kann SAST nicht beurteilen.
SAST liefert Dir also wertvolle und frühe Hinweise auf codebasierte Schwachstellen – ersetzt aber weder manuelle Code-Reviews noch ergänzende Tests wie DAST oder Penetrationstests, weil es nur einen Teil der nötigen Sicherheitsprüfungen abdeckt. Damit Dein Code am Ende keine Schwachstellen aufzeigt stellt die FIDA Dir die richtigen Experten zu Seite.

Bekannte SAST-Tools im Überblick
Der Markt für SAST-Tools ist breit aufgestellt – von kostenlosen Open-Source-Lösungen bis hin zu umfangreichen Enterprise-Plattformen. Die folgende Übersicht gibt Dir einen ersten Orientierungspunkt, ohne Anspruch auf Vollständigkeit:
SonarQube ist eines der bekanntesten und am weitesten verbreiteten Tools im Bereich statische Codeanalyse. Es kombiniert Codequalität und Sicherheit in einer Plattform und eignet sich sowohl für kleinere Teams als auch für Enterprise-Umgebungen. SonarQube wird im nächsten Abschnitt ausführlicher behandelt.
Semgrep ist ein schnelles, entwicklerfreundliches SAST-Tool mit einem besonderen Ansatz: Regeln werden in YAML geschrieben und sehen dem Code ähnlich, den sie suchen – das macht die Erstellung eigener Regeln besonders zugänglich. Die Community Edition ist kostenlos und für viele Teams ein guter Einstiegspunkt.
Checkmarx ist eine kommerzielle Enterprise-Lösung, die neben SAST auch DAST, SCA und weitere Sicherheitsfunktionen in einer Plattform bündelt. Sie richtet sich vor allem an große Organisationen mit komplexen Anforderungen an Compliance und Governance.
OpenText Fortify gilt als einer der Marktführer im Enterprise-Segment und bietet eine besonders tiefe Sprachunterstützung sowie umfangreiche Compliance-Reporting-Funktionen. Der Implementierungsaufwand ist im Vergleich zu anderen Tools höher, was Fortify vor allem für regulierte Branchen und Behörden relevant macht.
CodeQL ist das SAST-Tool von GitHub und für öffentliche Repositories kostenlos verfügbar. Es bietet eine semantische Codeanalyse und ist besonders eng in GitHub-Workflows integriert.
Die Wahl des richtigen Tools hängt von Faktoren wie Teamgröße, verwendeten Programmiersprachen, Budget und den Anforderungen an Compliance ab. Für viele Teams – besonders im Mittelstand – ist SonarQube ein sinnvoller Ausgangspunkt, da es einen guten Kompromiss aus Funktionsumfang, Integrierbarkeit und Einstiegshürde bietet. Du bist Dir unsicher, welches Tool für Dein Projekt oder Unternehmen das richtige ist? Kein Problem unsere Experten helfen Dir gerne weiter!
Wie funktioniert SAST mit SonarQube?
SonarQube ist ursprünglich als Tool zur Verbesserung der Codequalität gestartet und hat sich im Laufe der Zeit zu einer vollwertigen SAST-Plattform entwickelt. Heute wird es laut Herstellerangaben von über 7 Millionen Entwicklern und mehr als 400.000 Unternehmen weltweit eingesetzt. Wir bei der FIDA nutzen SonarQube für interne Projekte und unterstützen Unternehmen bei der Einführung und dem Betrieb von SonarQube.
Was analysiert SonarQube?
SonarQube untersucht Quellcode auf drei Kategorien von Problemen: Sicherheitslücken (Vulnerabilities), Code-Smells – also strukturelle Schwächen, die die Wartbarkeit beeinträchtigen – sowie Bugs. Unterstützt werden dabei unter anderem Java, JavaScript und PHP. Für die Sicherheitsanalyse setzt SonarQube auf eine eigene SAST-Engine, die unter anderem Datenflussanalyse und Taint-Tracking einsetzt, um Schwachstellen wie SQL-Injection, XSS oder die versehentliche Weitergabe von Secrets im Code zu erkennen. Die Regelbibliothek umfasst dabei über 6.000 Prüfregeln für mehr als 35 Programmiersprachen.
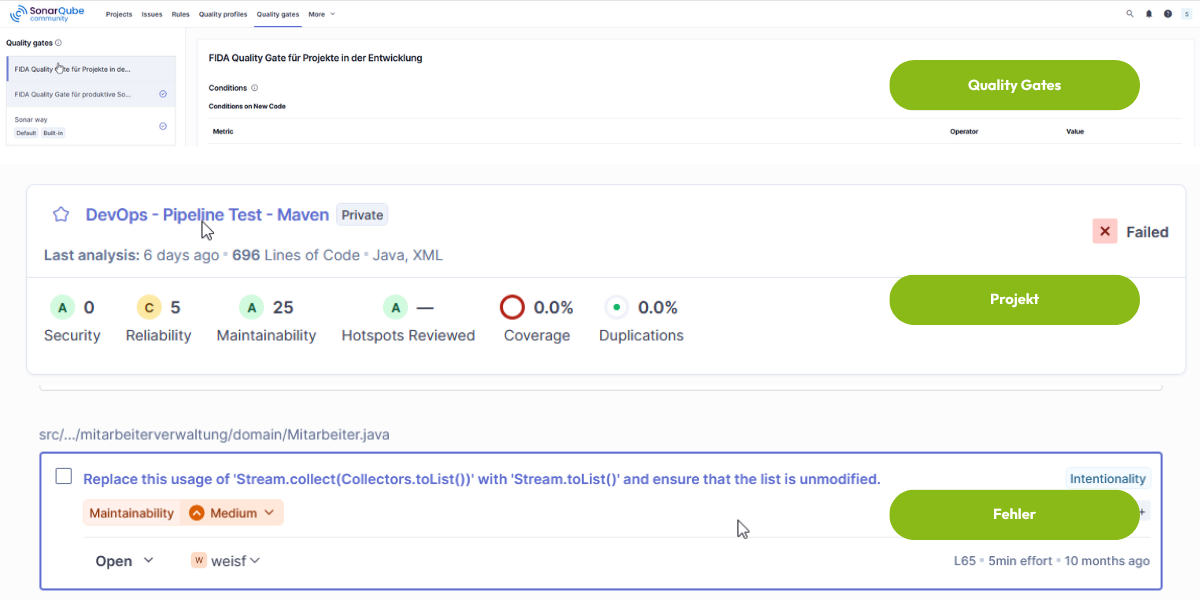
Was sind Quality Gates?
Ein zentrales Konzept in SonarQube sind sogenannte Quality Gates – definierbare Schwellenwerte, die festlegen, ab wann ein Build als „bestanden" gilt. Du kannst zum Beispiel festlegen, dass ein Pull Request nur dann in den Hauptbranch gemergt werden darf, wenn keine neuen kritischen Sicherheitslücken eingeführt wurden. Damit wird Sicherheit zu einem messbaren, automatisch durchgesetzten Qualitätskriterium im Entwicklungsprozess.
Wie kann SonarQube in den Entwicklungsworkflow integriert werden?
SonarQube lässt sich auf mehreren Ebenen in den Entwicklungsalltag einbinden. Über das Plugin SonarLint erhalten Entwickler direktes Feedback bereits in ihrer IDE – noch bevor Code committet wird. Darüber hinaus lässt sich SonarQube in alle gängigen CI/CD-Systeme integrieren, darunter Jenkins, GitLab CI, GitHub Actions und Azure DevOps. Bei jedem Commit oder Pull Request wird automatisch ein Scan ausgelöst, dessen Ergebnisse direkt im Code-Review sichtbar sind.
Wie führe ich SAST erfolgreich ein?
Die Entscheidung für ein SAST-Tool ist erst der Anfang. Damit die Einführung in der Praxis funktioniert und das Tool tatsächlich genutzt wird, sind einige Punkte zu beachten.
Das richtige Tool wählen
Nicht jedes SAST-Tool passt zu jedem Team. Relevante Auswahlkriterien sind unter anderem die unterstützten Programmiersprachen und Frameworks, die Integrierbarkeit in bestehende CI/CD- und IDE-Umgebungen sowie das Budget. Für viele Teams empfiehlt sich ein Proof of Concept: Das Tool wird zunächst auf einem realen Teilprojekt ausprobiert, bevor eine breitere Einführung erfolgt.
Klein anfangen, schrittweise ausweiten
Eine vollständige SAST-Einführung auf einmal ist selten sinnvoll. Besser ist ein schrittweises Vorgehen: zunächst einen Scan auf einem Projekt einrichten, die Ergebnisse bewerten, Regeln anpassen – und dann sukzessive weitere Projekte einbeziehen. So vermeidet Du, das Team von Anfang an mit einer Flut von Meldungen zu überfordern.
False Positives aktiv reduzieren
Eines der größten Akzeptanzprobleme bei SAST ist das sogenannte Alert Fatigue: Wenn Entwickler zu viele Meldungen erhalten, von denen ein Großteil irrelevant ist, werden sie beginnen, Ergebnisse zu ignorieren – auch echte Schwachstellen. Laut Branchenerhebungen produzieren nicht konfigurierte SAST-Tools False-Positive-Raten von 30 bis 60 Prozent. Mit gezielter Konfiguration und angepassten Regelsets lässt sich dieser Wert auf 10 bis 20 Prozent reduzieren. Der Aufwand dafür lohnt sich: Je präziser die Ergebnisse, desto höher die Akzeptanz im Team.
Das Entwicklungsteam einbinden
SAST funktioniert nur dann nachhaltig, wenn Entwicklerinnen und Entwickler die Ergebnisse verstehen und als hilfreich empfinden. Das bedeutet: Schulungen zu häufigen Schwachstellentypen, klare interne Richtlinien zum Umgang mit Scan-Ergebnissen und ein gemeinsames Verständnis dafür, welche Befunde als kritisch eingestuft werden. SAST sollte nicht als Kontrollinstrument wahrgenommen werden, sondern als Werkzeug, das die eigene Arbeit erleichtert.
Klare Prozesse definieren
Lege fest, welche Schwachstellenkategorien automatisch einen Build blockieren und welche zunächst nur gemeldet werden. Quality Gates – wie sie etwa SonarQube bietet – helfen dabei, diese Regeln technisch durchzusetzen, ohne den Entwicklungsfluss unnötig zu verlangsamen.
Unsere Experten begleiten Dich in jedem Schritt der Einführung von SAST in Deinem Projekt!

SAST mit FIDA umsetzen
Die Einführung von SAST ist mehr als eine technische Entscheidung – sie ist eine organisatorische. Welches Tool passt zu Deinem Stack? Wie integrierst Du Scans sinnvoll in Deine CI/CD-Pipeline? Wie schaffst Du Akzeptanz im Entwicklungsteam und reduzierst False Positives auf ein handhabbares Maß?
Genau bei diesen Fragen setzt die FIDA an. Als erfahrenes Beratungs- und Softwarehaus mit über 30 Jahren Projekterfahrung in der Softwareentwicklung begleiten wir Unternehmen nicht nur bei der Tool-Auswahl, sondern bei der nachhaltigen Integration von Sicherheitsprozessen in den gesamten Entwicklungslebenszyklus. Ob Versicherung, öffentlicher Dienst oder mittelständisches Unternehmen – wir kennen die spezifischen Anforderungen Deiner Branche und entwickeln gemeinsam mit Dir eine Sicherheitsstrategie, die zu Deinen Prozessen passt.
Du möchtest SAST in Deinem Unternehmen einführen oder Deine bestehenden Sicherheitsprozesse auf den Prüfstand stellen? Sprich uns an – wir freuen uns auf den Austausch.
Häufig gestellte Fragen zu SAST
Beide Verfahren analysieren Quellcode auf Fehler und Schwachstellen – aber auf sehr unterschiedliche Weise. Ein manueller Code-Review wird von einem Menschen durchgeführt, der den Code liest, bewertet und kommentiert. SAST hingegen ist ein automatisierter Prozess: Ein Tool durchsucht den Code systematisch nach bekannten Schwachstellenmustern, ohne dass ein Mensch jeden Codeabschnitt manuell prüfen muss. Beide Ansätze haben ihre Berechtigung. SAST ist schneller, skaliert mit dem Codeumfang und läuft konsistent bei jedem Commit. Ein manueller Code-Review kann dagegen Kontextwissen einbringen und Logikfehler erkennen, die einem automatisierten Tool verborgen bleiben. In der Praxis ergänzen sich beide Methoden.
Eine allgemeine gesetzliche Pflicht zum Einsatz von SAST gibt es aktuell nicht. Allerdings verweisen verschiedene Compliance-Frameworks und Sicherheitsstandards explizit auf statische Codeanalyse als empfohlene oder geforderte Maßnahme. So referenzieren Frameworks wie PCI-DSS und ISO 27001 die OWASP-Richtlinien, die SAST als Teil einer sicheren Softwareentwicklung vorsehen. Mit dem EU Cyber Resilience Act (CRA), der schrittweise in Kraft tritt, rücken Anforderungen an die Sicherheit von Software-Produkten zudem stärker in den gesetzlichen Fokus. Für Unternehmen in regulierten Branchen – etwa Versicherungen oder dem öffentlichen Dienst – ist der Einsatz von SAST daher zunehmend nicht nur empfehlenswert, sondern faktisch notwendig, um Audit-Anforderungen zu erfüllen.
Das hängt stark vom Tool, der Codebasis und dem Analyseumfang ab. Moderne, auf Entwickler ausgelegte Tools wie Semgrep sind für ihre Geschwindigkeit bekannt und scannen viele Projekte in Sekunden bis wenigen Minuten. Schwergewichtigere Enterprise-Tools wie Fortify oder Checkmarx benötigen bei großen Codebasen deutlich länger – teils mehrere Stunden. In der Praxis empfiehlt sich ein inkrementeller Ansatz: Bei jedem Commit wird nur der geänderte Code gescannt, ein vollständiger Scan der gesamten Codebasis erfolgt seltener, etwa nächtlich oder vor einem Release.
Ja, grundsätzlich schon. Die meisten modernen SAST-Tools unterstützen eine breite Palette an Programmiersprachen – auch ältere. Allerdings gilt: Je älter und unstrukturierter der Code, desto höher ist in der Regel die False-Positive-Rate, weil das Tool den spezifischen Kontext veralteter Frameworks und Bibliotheken nicht vollständig kennt. Es lohnt sich, vor der Einführung zu prüfen, ob das gewählte Tool die im Legacy-System verwendeten Sprachen und Frameworks offiziell unterstützt. Ein gezieltes Pilotprojekt auf einem Teilbereich des Legacy-Codes hilft, realistische Erwartungen zu setzen.
Ja – und gerade für kleinere Teams kann SAST besonders wertvoll sein, weil dort oft keine dedizierten Security-Spezialisten vorhanden sind. Mit einem kostenfreien Tool wie der SonarQube Community Edition oder Semgrep lässt sich ein SAST-Scan mit überschaubarem Aufwand einrichten. Der Einstieg muss nicht groß sein: Auch ein einzelner Scan in der CI-Pipeline, der kritische Schwachstellen meldet, liefert sofort Mehrwert. Der Aufwand für Konfiguration und Pflege lässt sich schrittweise ausbauen.
Ein SAST-Scan liefert in der Regel eine Liste von Befunden, klassifiziert nach Schweregrad – von kritisch bis niedrig. Empfehlenswert ist folgendes Vorgehen: Zunächst alle kritischen und hohen Befunde priorisieren und auf tatsächliche Relevanz prüfen – nicht jeder Befund ist automatisch ein echtes Sicherheitsrisiko. Dann die bestätigten Schwachstellen beheben und den Scan erneut ausführen, um die Behebung zu verifizieren. Befunde, die als False Positives eingestuft werden, sollten dokumentiert und im Tool entsprechend markiert werden, damit sie künftige Scan-Ergebnisse nicht unnötig belasten. Langfristig gilt: SAST-Ergebnisse sollten regelmäßig im Team besprochen werden, um ein gemeinsames Sicherheitsbewusstsein zu entwickeln.
Das ist eine zunehmend relevante Frage. KI-generierter Code – etwa aus GitHub Copilot oder ähnlichen Tools – unterliegt denselben Schwachstellenmustern wie manuell geschriebener Code. SAST analysiert den Code als solchen, unabhängig davon, ob er von einem Menschen oder einer KI stammt. Sonar etwa bewirbt SonarQube explizit als geeignet zur Analyse von KI-generiertem Code. Da KI-Assistenten gelegentlich unsichere Codemuster produzieren, ist der automatisierte Scan mit SAST gerade in Projekten, die stark auf KI-Code-Generierung setzen, ein sinnvoller Kontrollmechanismus.
Grundsätzlich gilt: so früh und so häufig wie möglich. In der Praxis hat sich folgendes Modell bewährt: Bei jedem Commit oder Pull Request wird ein inkrementeller Scan des geänderten Codes durchgeführt. Zusätzlich wird regelmäßig – etwa täglich oder wöchentlich – ein vollständiger Scan der gesamten Codebasis angestoßen, um auch schleichende Probleme oder neu hinzugekommene Regeln zu berücksichtigen. Vor jedem Release empfiehlt sich ein finaler Scan als Quality Gate, bevor Code in die Produktion geht.
Die Kosten hängen stark vom gewählten Tool und dem Einführungsaufwand ab. Auf der Tool-Seite gibt es sowohl vollständig kostenfreie Open-Source-Lösungen (SonarQube Community Edition, Semgrep Community) als auch kommerzielle Produkte, deren Preise je nach Unternehmensgröße und Funktionsumfang erheblich variieren. Hinzu kommt der interne Aufwand für Einrichtung, Konfiguration, Schulung und laufende Pflege. Für viele Teams – insbesondere im Mittelstand – ist der Einstieg mit einem kostenlosen Tool realistisch und sinnvoll. Wer eine umfassendere Einführung plant oder spezifische Compliance-Anforderungen erfüllen muss, profitiert von einer begleiteten Implementierung, wie sie die FIDA anbietet.



