
Was ist Deep Learning? Definition - Funktionsweise - Anwendung
Hast Du Dich schon mal gefragt, warum Smartphones heute Gesichter erkennen, Autos selbstständig fahren können oder Chatbots immer natürlicher wirken? Hinter vielen dieser kleinen technischen Wunder steckt Deep Learning – eine Art „Gehirn“ für moderne KI-Systeme. Deep Learning ist dabei nur ein Teilbereich der künstlichen Intelligenz, der komplexe Daten interpretieren kann und automatisierte Lernprozesse ermöglicht.
Deep Learning ist längst kein Zukunftsthema mehr. Es ist heute ein zentraler Baustein der modernen KI-Forschung und -Anwendung. Es beeinflusst Deinen Alltag – oft, ohne dass Du es überhaupt bemerkst. In diesem Beitrag zeige ich Dir auf verständliche Weise, was Deep Learning wirklich ist, warum es so mächtig ist und wie es unsere Welt gerade völlig neu sortiert.
Dieser Artikel bietet Dir einen verständlichen Überblick über Deep Learning und hilft Dir, die Grundlagen und Potenziale dieser Technologie besser zu verstehen.

Was ist Deep Learning? - Eine Definition
Deep Learning basiert auf neuronalen Netzen, die komplexe Rechenstrukturen darstellen und aus vielen hintereinandergeschalteten Schichten bestehen. Jede der vielen Schichten (sogenannte Hidden Layer) verarbeitet die Informationen der vorhergehenden Schicht weiter. In diesem hierarchischen Prozess werden in jeder Stufe automatisch und aufeinanderfolgend immer abstraktere Merkmale (Features) aus den Daten extrahiert und erkannt. Die Funktionsweise von Deep Learning basiert auf der automatisierten Extraktion von hierarchischen Merkmalen und der nachfolgenden Mustererkennung in großen Datensätzen, um daraus selbstständig Entscheidungen oder Vorhersagen abzuleiten.
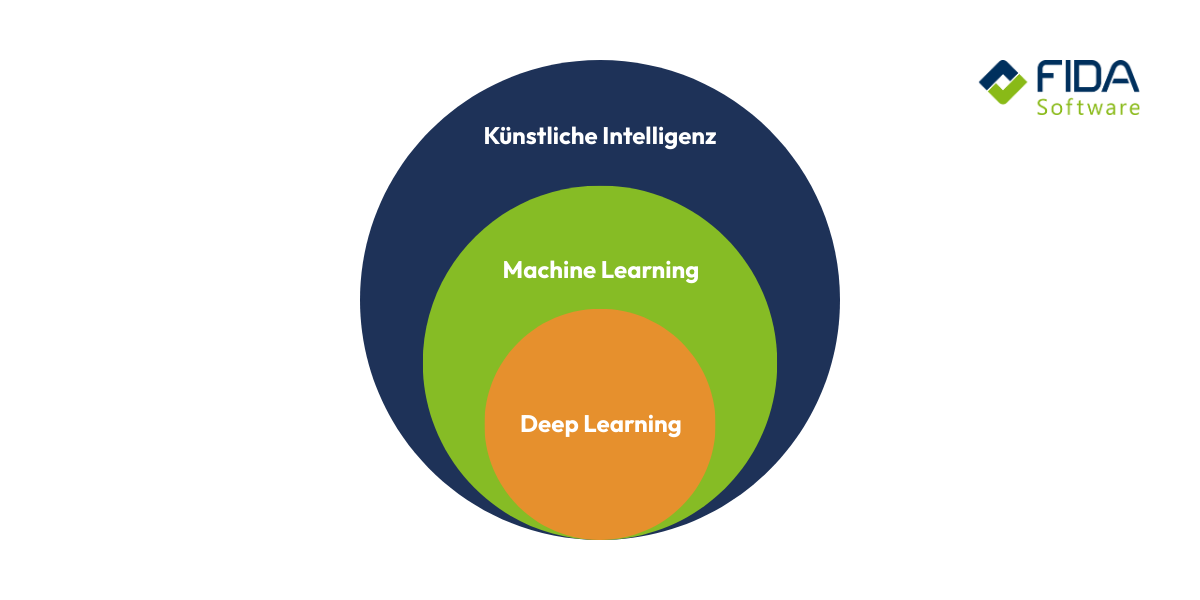
Was ist der Unterschied zwischen Deep Learning und Machine Learning?
Machine Learning (ML) ist der Überbegriff für alle Methoden der Künstlichen Intelligenz, die es einem System ermöglichen, aus Daten zu lernen und ohne explizite Programmierung Vorhersagen zu treffen oder Entscheidungen zu treffen. Deep Learning (DL) ist eine Unterkategorie des Machine Learning. Der Hauptunterschied liegt in der Architektur der verwendeten Modelle: ML verwendet Modelle mit einfacheren, flacheren Architekturen, während DL tiefe neuronale Netze nutzt, die aus einer Vielzahl von Schichten (Hidden Layern) bestehen.
Die Art und Weise, wie ein Modell lernt, wird durch sogenannte Lernparadigmen definiert. Diese Paradigmen sind unabhängig davon, ob es sich um ein klassisches ML-Modell oder ein DL-Modell handelt.
Zu den wichtigsten Lernparadigmen gehören:
Supervised Learning (Überwachtes Lernen): Das Modell wird mit Daten trainiert, denen die korrekte Lösung (Label) bereits beigefügt ist. Das Ziel ist es, die Zusammenhänge zwischen den Eingabedaten und den Labels zu lernen. (Beispiel: Spam-Erkennung, Klassifizierung von Bildern)
Unsupervised Learning (Unüberwachtes Lernen): Das Modell erhält Daten ohne vorgegebene Labels oder Ziele. Es soll selbstständig Muster, Strukturen oder Ähnlichkeiten in den Daten erkennen. (Beispiel: Kundensegmentierung, Clustering von Dokumenten)
Reinforcement Learning (Bestärkendes Lernen): Das Modell lernt, indem es in einer Umgebung agiert und durch Belohnungen oder Bestrafungen für seine Entscheidungen Feedback erhält. (Beispiel: Autonomes Fahren, Spiele wie Go oder Schach)
Obwohl sich Aufgaben, die mit klassischem Machine Learning gelöst werden können, prinzipiell auch mit Deep Learning bewältigen lassen, kann der Einsatz von mächtigen neuronalen Netzen in einfachen Fällen übertrieben sein ("mit Kanonen auf Spatzen schießen").
Für sehr komplexe Aufgaben und extrem große Datenmengen können Deep-Learning-Modelle tendenziell besser skaliert werden als klassische Machine-Learning-Modelle, da ihre Architektur darauf ausgelegt ist, aus der Datenfülle automatisch tiefergehende Merkmale zu extrahieren.
Hinsichtlich der Leistungsentwicklung ist zu beachten: Während sowohl Machine-Learning- als auch Deep-Learning-Modelle irgendwann ein Leistungsplateau erreichen, ermöglicht die höhere Kapazität von DL-Netzwerken, dass sie im Vergleich zu flacheren ML-Modellen tendenziell später an diesen Punkt gelangen und somit von mehr Daten profitieren können. Es ist jedoch wichtig zu betonen, dass mehr Daten nicht automatisch immer eine bessere Leistung garantieren. Unzureichende Datenqualität oder eine ungeeignete Modellkonfiguration können die Leistung eines Modells – egal ob ML oder DL – negativ beeinflussen oder sogar zu einer Degeneration führen.
Deep Learning und Machine Learning unterscheiden sich somit primär in der Architektur und der damit verbundenen Fähigkeit zur automatisierten, hierarchischen Merkmalsextraktion aus unstrukturierten oder sehr komplexen Daten, nicht in den grundlegenden Lernparadigmen.

Wie funktioniert Deep Learning?
Um zu verstehen, wie Deep Learning arbeitet, kannst Du Dir künstliche neuronale Netze wie eine vereinfachte digitale Version unseres Gehirns vorstellen. Die Leistungsfähigkeit von Deep Learning beruht auf der engen Zusammenarbeit vieler komplexer Netzwerken, die gemeinsam große Datenmengen verarbeiten und Muster erkennen. Jedes Netz besteht aus vielen kleinen „Neuronen“, die Daten verarbeiten. Diese Neuronen nutzen Eingabewerte, Gewichte und sogenannte Bias-Werte, um Muster zu erkennen – ganz so, als würden sie Schritt für Schritt lernen, was in den Daten steckt.
Ein tiefes neuronales Netz besteht dabei aus mehreren hintereinander geschalteten Schichten. Jede Schicht baut auf den Ergebnissen der vorherigen auf und macht die Erkennung immer genauer. Wenn Daten durch dieses Netz nach vorne fließen – von der Eingabeschicht bis zur Ausgabe – nennt man das Forward Propagation. Die Ausgabeschicht ist dabei die letzte Schicht des neuronalen Netzes und liefert das endgültige Ergebnis des Modells.
Damit das Netz aber wirklich „klug“ wird, braucht es Training. Hier kommt die Backpropagation ins Spiel. Dabei überprüft das Modell seine eigenen Fehler, berechnet, wie stark es daneben lag, und passt die Gewichte in den Schichten Schritt für Schritt an. Für die Optimierung der Gewichte werden spezielle Algorithmen eingesetzt, die es ermöglichen, auch komplexe Zusammenhänge in großen Datensätzen zu erfassen. Dieser Prozess läuft so lange, bis die Vorhersagen immer genauer werden. Du kannst es Dir wie einen Lernprozess vorstellen: ausprobieren, Fehler machen, anpassen – und wieder von vorn.
Exkurs: All das ist extrem rechenintensiv. Deep Learning benötigt enorme Power, weshalb oft GPUs eingesetzt werden. Diese Spezialprozessoren schaffen es, riesige Datenmengen parallel zu verarbeiten. Auch Cloud-Dienste helfen dabei, die nötige Rechenleistung bereitzustellen – vor allem, wenn viele GPUs zusammenarbeiten sollen. Auf Softwareseite kommen heute vor allem Frameworks wie JAX, PyTorch oder TensorFlow zum Einsatz, mit denen Deep-Learning-Modelle entwickelt und trainiert werden.
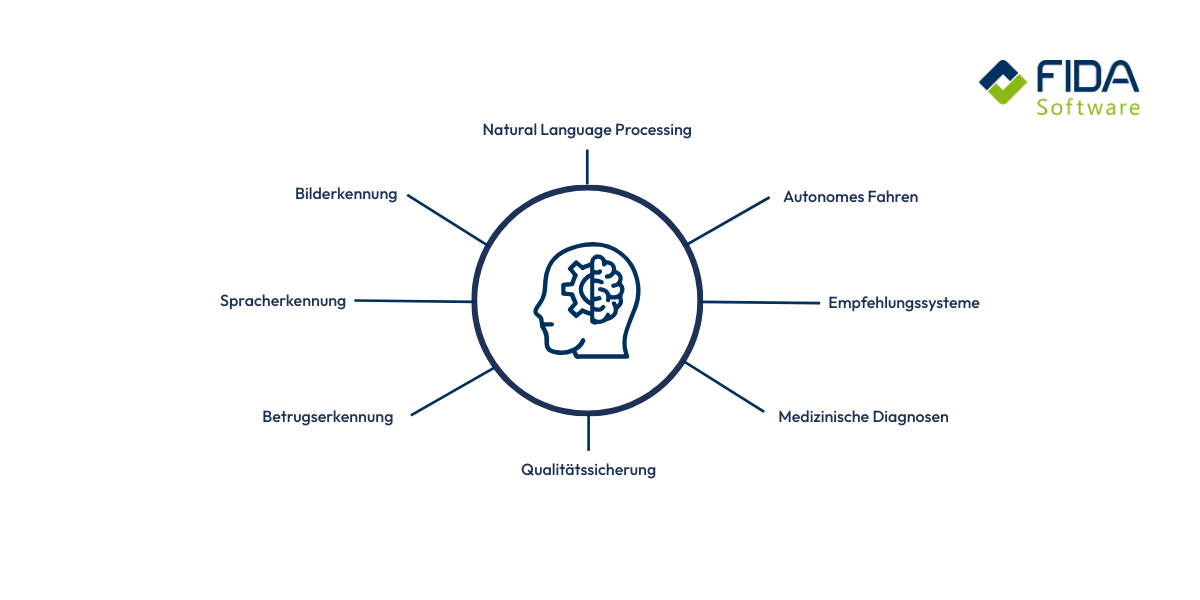
Wofür wird Deep Learning genutzt?
Deep Learning begegnet Dir heute in unzähligen Bereichen – oft ohne dass Du es bewusst bemerkst. Wenn Dein Smartphone Gesichter erkennt, Streaming-Dienste Dir passgenaue Empfehlungen geben oder Navigations-Apps den Verkehr vorhersagen, steckt meist Deep Learning dahinter. In der Medizin hilft die Technologie dabei, Krankheiten auf Bildern schneller zu erkennen. In der Industrie sorgt sie dafür, dass Maschinen Fehler automatisch entdecken oder Produktionsprozesse effizienter ablaufen. Selbstfahrende Autos verlassen sich auf Deep Learning, um ihre Umgebung zu verstehen. Kurz gesagt: Überall dort, wo große Datenmengen ausgewertet und komplexe Muster erkannt werden müssen, ist Deep Learning das Werkzeug, das all das erst möglich macht.

1. Bild- und Objekterkennung
Deep Learning kann Bilder analysieren und Objekte darauf erkennen – präzise und in Sekundenbruchteilen. Du kennst das vielleicht aus Deinem Smartphone, wenn die Kamera automatisch Gesichter erkennt oder Motive wie Himmel, Pflanzen oder Tiere identifiziert. In der Medizin wird dieselbe Technologie genutzt, um Tumore oder Auffälligkeiten auf MRT- oder Röntgenbildern zu finden – oft schneller und zuverlässiger als das menschliche Auge.

2. Sprach- und Textverarbeitung
Ob Übersetzungs-Apps, Chatbots oder virtuelle Assistenten – Deep Learning sorgt dafür, dass Maschinen Sprache verstehen und selbstständig Antworten generieren. Insbesondere moderne Transformer-Modelle (die Basis von Large Language Models/LLMs wie ChatGPT) haben in diesem Bereich einen Durchbruch erzielt. Wenn Du Dein Smartphone bittest, Dich an etwas zu erinnern, oder wenn Du Texte automatisch übersetzen lässt, arbeitet im Hintergrund ein Deep-Learning-Modell, das Sprache in Bedeutung umwandelt.

3. Personalisierte Empfehlungen
Streamingdienste wie Netflix oder Spotify nutzen Deep Learning, um Dir Filme, Serien oder Songs vorzuschlagen, die zu Deinem Geschmack passen. Auch Onlineshops setzen die Technologie ein, um Dir Produkte anzuzeigen, die Du tatsächlich interessant findest. Das System lernt aus Deinem Verhalten – was Du anschaust, klickst oder kaufst – und verbessert seine Vorschläge ständig.

4. Autonomes Fahren
Damit ein Auto selbstständig fahren kann, muss es seine Umgebung exakt „verstehen“. Kameras, Sensoren und Radar liefern riesige Datenmengen – Deep Learning analysiert sie in Echtzeit und erkennt Fußgänger, andere Fahrzeuge, Verkehrsschilder oder Hindernisse. Nur durch diese schnelle Verarbeitung kann ein Fahrzeug sicher und zuverlässig reagieren.

5. Qualitätssicherung in der Industrie
Maschinen in modernen Fabriken nutzen Deep Learning, um Fehler in Produkten frühzeitig zu erkennen oder Abläufe zu optimieren. Eine Kamera kann etwa jedes Bauteil prüfen und Unregelmäßigkeiten sofort melden. Das spart Kosten, erhöht die Qualität und macht die Prozesse effizienter.

6. Finanzwelt und Betrugserkennung
Banken und Zahlungsanbieter setzen Deep Learning ein, um ungewöhnliche Transaktionen aufzuspüren.
Das System erkennt Muster im Verhalten – und schlägt Alarm, wenn etwas nicht passt.
So wird verhindert, dass betrügerische Zahlungen durchrutschen.

Welche Typen von Deep-Learning-Modellen gibt es?
Die Architektur eines neuronalen Netzes bestimmt, welche Art von Daten es am besten verarbeiten kann. Die wichtigsten Modelle im Deep Learning sind:
1. Convolutional Neural Networks (CNNs)
CNNs sind die Standardarchitektur für die Bildverarbeitung. Sie nutzen spezielle Filter (Convolutional Layer), um hierarchisch Merkmale wie Kanten, Formen und Texturen aus Pixeldaten zu extrahieren.
Vorteile: Exzellent für Bild- und Mustererkennung.
Nachteile: Weniger geeignet für sequenzielle Daten (Text, Zeitreihen).
2. Rekurrente Neuronale Netze (RNNs)
RNNs sind speziell für die Verarbeitung von sequenziellen Daten (Zeitreihen, Sprache) konzipiert, da sie Informationen aus vorherigen Schritten speichern können. Moderne Varianten wie LSTMs (Long Short-Term Memory) lösen die Probleme früherer RNNs.
Vorteile: Gut für Sequenzen, Vorhersagen von Zeitreihen.
Nachteile: Langsames Training, Probleme bei sehr langen Abhängigkeiten.
3. Autoencoder & Variational Autoencoder (VAEs)
Autoencoder bestehen aus einem Encoder (der Daten komprimiert) und einem Decoder (der sie wieder rekonstruiert). Sie dienen primär der Dimensionsreduktion und der Anomalieerkennung, indem sie lernen, die "normalen" Daten möglichst gut darzustellen.
Vorteile: Effektive Datenkompression, gut für die Bereinigung von Rauschen und Anomalieerkennung.
Nachteile: Die Qualität der Rekonstruktion hängt stark von der Kompressionsrate ab.
4. Generative Adversarial Networks (GANs)
GANs bestehen aus zwei Netzen – einem Generator und einem Diskriminator –, die in einem Wettbewerb gegeneinander trainieren. Der Generator erzeugt neue, realistische Daten (z. B. Bilder), während der Diskriminator versucht, die gefälschten Daten zu erkennen.
Vorteile: Sehr leistungsstark und perfekt für generative Aufgaben.
Nachteile: Training ist anspruchsvoll und instabil, benötigt viele Daten.
5. Diffusionsmodelle
Diffusionsmodelle erzeugen Bilder, indem sie schrittweise Rauschen entfernen – ein Prozess, der sehr stabile und hochwertige Ergebnisse liefert. Viele moderne Bildgeneratoren nutzen dieses Prinzip.
Vorteile: Sehr hohe Bildqualität, stabileres Training als GANs.
Nachteile: Training kann extrem rechenintensiv sein; Modelle brauchen viel Feintuning.
6. Transformer-Modelle
Transformer haben das moderne KI-Zeitalter geprägt. Sie verarbeiten Text parallel statt Wort für Wort und verstehen so komplexe Zusammenhänge in Sprache. Diese Architektur steckt heute hinter Chatbots, Übersetzern, Textklassifizierung, Zusammenfassungen – und hinter großen Sprachmodellen wie ChatGPT.
Vorteile: Schnell, hoch skalierbar, hervorragend im Umgang mit Sprache und langen Kontexten.
Nachteile: Enorme Trainingskosten, großer Bedarf an hochwertigen Daten.

Deep Learning verstehen – Dein Einstieg in die KI-Zukunft
Deep Learning ist heute einer der spannendsten Bereiche der Künstlichen Intelligenz. Ob Bilderkennung, Sprachverarbeitung oder autonome Systeme – überall dort, wo große Datenmengen verarbeitet und komplexe Muster erkannt werden müssen, spielt diese Technologie ihre Stärken aus. Du hast gesehen, wie Deep Learning funktioniert, welche Modellarten es gibt und worin es sich vom klassischen Machine Learning unterscheidet. Vor allem aber wird deutlich: Je höher die Datenqualität und die Kapazität eines neuronalen Netzes sind, desto präziser und leistungsfähiger kann es werden.
Wenn Du tiefer in die Welt der KI einsteigen willst, findest Du in der FIDAcademy genau die richtige Unterstützung. Dort erwarten Dich praxisnahe Trainings und Weiterbildungen rund um Themen wie Künstliche Intelligenz, neuronale Netze und moderne Machine-Learning-Methoden. So kannst Du Dein Wissen gezielt ausbauen und die Technologien verstehen, die unsere digitale Zukunft gestalten.
FAQ - Häufige Fragen zum Thema Deep Learning
Deep Learning ist ein Teilgebiet der Künstlichen Intelligenz, das auf künstlichen neuronalen Netzen mit vielen Schichten basiert. Diese komplexen Rechenstrukturen können hierarchisch Merkmale in großen Datenmengen erkennen und selbstständig lernen.
Deep Learning ist eine Unterkategorie von Machine Learning und unterscheidet sich primär in der Architektur (tiefe Netze). Beim klassischen Machine Learning müssen Merkmale häufig manuell definiert werden, während Deep Learning-Modelle relevante Merkmale direkt aus den Rohdaten lernen. Die grundlegenden Lernparadigmen (wie Supervised Learning) sind unabhängig von ML oder DL.
Neuronale Netze verarbeiten Daten Schicht für Schicht. Das Modell ermittelt beim Training Fehler und passt seine Gewichte mittels Backpropagation an. So verbessert es Schritt für Schritt seine Vorhersagen. Häufig wird dafür spezielle Hardware wie GPUs benötigt.
Deep Learning wird unter anderem eingesetzt für:
Bild- und Objekterkennung
Sprachverarbeitung und Chatbots (insbesondere Transformer-Modelle)
Empfehlungssysteme
Autonomes Fahren
Anomalie- und Betrugserkennung
Qualitätskontrolle in der Industrie
Zu den wichtigsten Modelltypen gehören:
Convolutional Neural Networks (CNNs)
Rekurrente Neuronale Netze (RNNs)
Autoencoder
Generative Adversarial Networks (GANs)
Diffusionsmodelle
Transformer-Modelle
Deep-Learning-Modelle benötigen oft sehr viele hochwertige Daten, viel Rechenleistung und können schwer interpretierbar sein. Zudem besteht das Risiko der Degeneration oder Überanpassung, wenn Datenqualität oder -vielfalt nicht ausreichend sind.
Nein. Bei kleineren oder strukturierten Datensätzen kann klassisches Machine Learning effizienter und leichter handhabbar sein. Deep Learning lohnt sich besonders für unstrukturierte Daten wie Bilder, Sprache oder Text.
Beliebte Frameworks sind z. B. TensorFlow, PyTorch und JAX. Sie erleichtern das Erstellen, Trainieren und Deployen von neuronalen Netzen..



