
Che cos'è Machine Learning (l'apprendimento automatico) e come può essere utilizzato?
Forse conoscete la sensazione: aprite Netflix e trovate subito una serie che si adatta perfettamente ai vostri gusti. Oppure il vostro smartphone organizza le vostre foto in modo così intelligente da permettervi di trovare determinati momenti con un solo tocco. Forse starete pensando: "È davvero comodo". Ed è proprio questo il senso dell'apprendimento automatico (Machine Learning). Machine Learning si è evoluto da un concetto fantascientifico a un componente centrale dell'elaborazione delle informazioni di oggi.
Machine Learning non è più uno scenario futuro, ma vi accompagna ogni giorno, in modo discreto ma incredibilmente efficace. Vi aiuta a risparmiare tempo, a prendere decisioni migliori e a ottenere informazioni adatte alle vostre esigenze. E più ci si confronta con essa, più ci si rende conto di quanto questa tecnologia stia cambiando il nostro mondo.
Cosa rende Machine Learning così speciale? I computer imparano le cose senza che sia necessario spiegare loro ogni singolo passo. Gli algoritmi eseguiti sui computer elaborano grandi quantità di dati e automatizzano le attività riconoscendo gli schemi e prendendo decisioni. Riconoscono schemi, fanno previsioni e accelerano così i processi aziendali. E questo non solo apre nuove possibilità per voi nella vita di tutti i giorni, ma soprattutto per le aziende, grandi e piccole. I processi si svolgono in modo più fluido, i dati vengono utilizzati in modo più efficace e le attività che prima richiedevano molto tempo vengono ora eseguite da un sistema in modo quasi incidentale, dove il compito esatto è decisivo per il modello di Machine Learning utilizzato.
In questo articolo, unisciti a noi in un viaggio dietro le quinte dell'intelligenza artificiale.
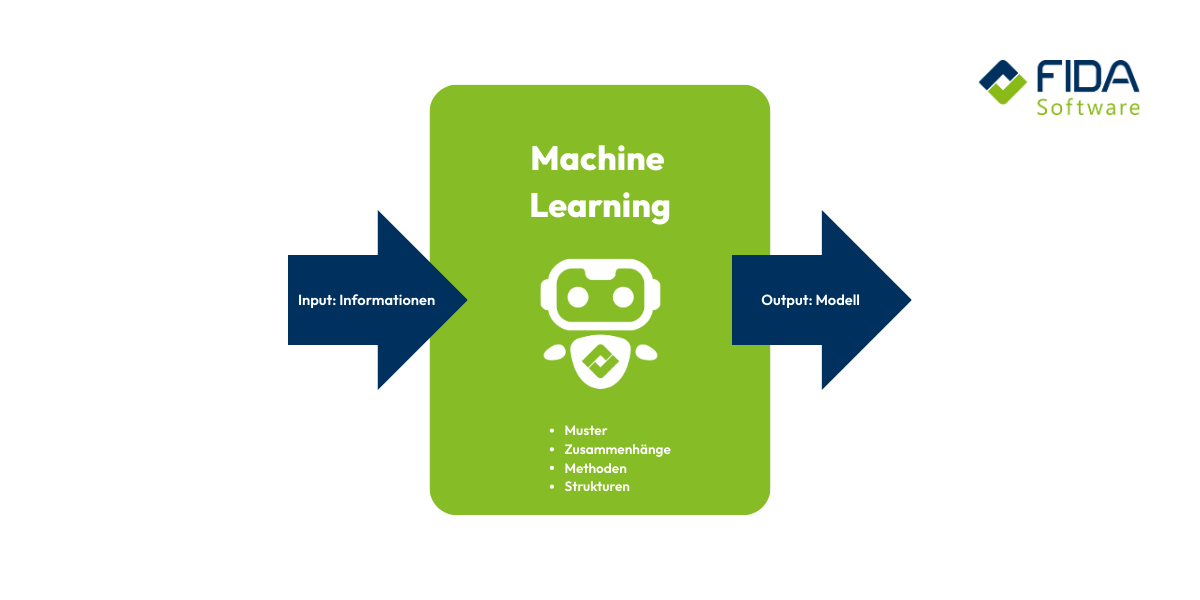
Che cosa significa in realtà Machine Learning?
Se vi siete mai chiesti come i computer riescano a diventare più intelligenti grazie all'esperienza, allora Machine Learning è l'argomento giusto per voi. Machine Learning (ML) è una sottoarea dell'intelligenza artificiale. Questi termini sono spesso usati insieme, quindi è importante distinguere tra i singoli termini come machine learning, deep learning e AI. L'obiettivo è sviluppare sistemi che imparino dai dati, riconoscano gli schemi e si migliorino nel tempo senza che nessuno debba programmare ogni singolo passaggio.
L'intelligenza artificiale è quindi il termine generale. Descrive le tecnologie che tentano di replicare il pensiero umano, sia attraverso regole ben definite che attraverso algoritmi di apprendimento. Ecco perché AI e machine learning vengono spesso citati nella stessa frase, anche se non sono la stessa cosa. La definizione di Machine Learning costituisce una base importante per comprendere i termini e le correlazioni all'interno dell'intelligenza artificiale.
La si può ricordare così: Machine Learning è un approccio speciale all'interno dell'IA, ma non tutte le IA funzionano con Machine Learning.

Machine Learning e apprendimento profondo: qual è la differenza?
Avrete notato che i termini machine learning e deep learning sono spesso usati in modo intercambiabile nella vita quotidiana. Non c'è da stupirsi, perché entrambi fanno parte dell'intelligenza artificiale. Tuttavia, esistono importanti differenze che vi aiuteranno a classificare meglio la tecnologia.
Fondamentalmente, è possibile visualizzare la relazione in questo modo: Machine Learning è il grande termine ombrello - che include le reti neurali - e l'apprendimento profondo è un'area specializzata di queste reti neurali. L'apprendimento profondo è una sottoarea dell'Machine Learning caratterizzata da strutture particolarmente complesse e da grandi quantità di dati.

Come funziona Machine Learning?
Machine Learning funziona in modo simile al vostro processo di apprendimento: il sistema migliora nel tempo attraverso la ripetizione, le prove e gli errori e il feedback. All'inizio, l'algoritmo riceve il supporto degli esseri umani o di una serie di dati ben curati, mentre in seguito prende decisioni in modo indipendente. Il processo può essere facilmente suddiviso in alcune fasi.
Nel cosiddetto processo di Machine Learning, le singole fasi - dalla raccolta dei dati, allo sviluppo e all'addestramento del modello, all'ottimizzazione e all'implementazione - vengono eseguite sistematicamente. Il processo di Machine Learning richiede una grande quantità di dati di alta qualità per ottenere risultati precisi.

1° addestramento: il sistema impara dagli esempi
Per prima cosa, si alimenta il modello con un set di dati di addestramento. I set di dati di grandi dimensioni sono fondamentali in questo caso, poiché costituiscono la base per l'addestramento e l'ottimizzazione dei modelli di Machine Learning. Questi dati provengono da voi o dal vostro team e aiutano l'algoritmo a riconoscere modelli, correlazioni e regole. Più gli esempi sono numerosi e diversificati, meglio il sistema potrà lavorare in seguito.
La qualità e la quantità dei set di dati sono decisive per le prestazioni del modello. I singoli punti di dati vengono utilizzati per affinare il modello in modo mirato e consentire previsioni più precise. I dati campione svolgono un ruolo centrale nell'addestramento di vari metodi di apprendimento, in quanto aiutano il modello a riconoscere i modelli rilevanti. La quantità di dati influenza in modo significativo l'accuratezza e la formazione del modello. Nell'apprendimento automatico, spesso vengono elaborate grandi quantità di dati per migliorare continuamente i modelli e consentire processi automatizzati.
Si può pensare a questa fase come a una "pratica": A ogni esecuzione, la qualità dei risultati migliora.
2 Apprendimento iterativo: passo dopo passo verso una maggiore precisione
Machine Learning è un processo continuo. Il modello ripete i suoi compiti finché non raggiunge un certo livello di precisione. In questa fase, le prestazioni del sistema sono costantemente monitorate. Se necessario, è possibile intervenire, regolare o fornire ulteriori dati per migliorare ulteriormente i risultati. L'intervento umano è fondamentale per monitorare e ottimizzare il processo di formazione, in modo da garantire costantemente la qualità e l'accuratezza dei modelli.
3 Riconoscere e correggere gli errori
Se il modello fa una previsione errata, questo errore viene utilizzato per adattare ulteriormente il sistema. I parametri interni cambiano: è così che il modello adatta il suo "modo di pensare".
A ogni correzione, diventa un po' più preciso e impara a riconoscere i modelli corretti in modo affidabile, diventando sempre più capace di riconoscere modelli complessi.
4° utilizzo: il modello lavora in modo indipendente
Non appena la precisione è sufficientemente elevata, è possibile utilizzare il modello nella pratica. Il modello ML analizza i nuovi dati, riconosce gli schemi e supporta così decisioni fondate nei rispettivi processi aziendali. Ora è in grado di gestire nuovi dati, precedentemente sconosciuti, e di fare previsioni o supportare decisioni in modo indipendente. Il sistema utilizza le conoscenze apprese per reagire in tempo reale e fornire risultati sempre migliori.
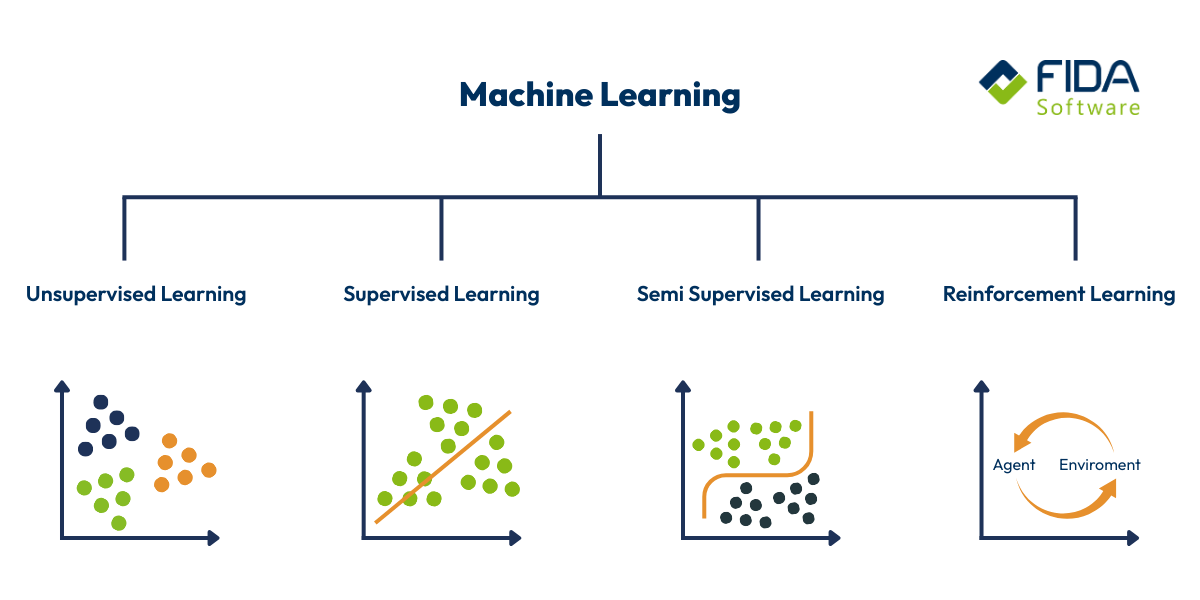
Quali tipi di Machine Learning esistono?
Non tutto Machine Learning è uguale. Esistono diversi approcci che hanno punti di forza molto diversi a seconda dell'obiettivo, della situazione dei dati e dell'impegno richiesto. Questi approcci possono assumere diverse forme di Machine Learning, ognuna delle quali offre applicazioni e vantaggi specifici per diversi settori. Per capire meglio quale sia l'approccio più adatto, diamo un'occhiata più da vicino ai quattro tipi più importanti.
Apprendimento supervisionato
Nell'apprendimento supervisionato, l'algoritmo riceve una sorta di "aiuto all'apprendimento": i dati che gli vengono forniti sono già etichettati. Vengono utilizzati diversi metodi di apprendimento e algoritmi di Machine Learning per sviluppare il modello ottimale per il compito da svolgere.
Un esempio tipico è il filtro antispam. In questo caso, il modello impara da molte e-mail che sono già state etichettate come "spam" o "non spam", in modo che il modello sia addestrato a fare previsioni il più possibile accurate. Il modello svolge un ruolo centrale nell'analisi e nella categorizzazione dei dati, riconoscendo gli schemi e utilizzandoli per le decisioni future.
È importante che i dati di addestramento siano rappresentativi del mondo reale. Se i dati contengono solo esempi idealizzati e non mostrano alcuna varianza naturale, il modello non apprende la realtà in modo sufficientemente completo. Se i modelli sono troppo complessi, c'è anche il rischio di overfitting: il modello impara i dati di addestramento praticamente a memoria, ma non può applicare la conoscenza a nuove email sconosciute.
Esempi di applicazione:
Filtraggio delle e-mail: classificazione delle e-mail come spam o non spam.
Diagnostica medica: previsione di malattie in base ai sintomi.
Analisi finanziaria: previsione dei prezzi delle azioni.
Riconoscimento di immagini: identificazione di oggetti in immagini.
Apprendimento non supervisionato
Nell'apprendimento non supervisionato, l'algoritmo è completamente abbandonato a se stesso. Gli si forniscono dati non etichettati, senza risposte giuste o sbagliate, e lui stesso cerca di riconoscere schemi e correlazioni. La comprensione delle relazioni tra le variabili è fondamentale per estrarre informazioni rilevanti dai dati.
Per ottenere nuove conoscenze dai dati non strutturati e per visualizzare le correlazioni si utilizzano diversi modelli e metodi. L'applicazione pratica dell'apprendimento non supervisionato è visibile, ad esempio, nelle aziende che lo utilizzano per ottimizzare i processi o nella vita quotidiana, come nell'ordinamento automatico delle foto.
L'approccio è particolarmente adatto alla formazione di gruppi (cluster) o all'identificazione di modelli insoliti (anomalie). Le funzioni di raccomandazione nei negozi lavorano spesso con questo approccio. Ad esempio, riconoscono: "I clienti che hanno acquistato questo prodotto sono interessati anche a ...".
L'apprendimento non supervisionato è molto utile anche per il rilevamento delle frodi. Se il sistema rileva modelli che si discostano significativamente dalla norma, lancia l'allarme.
Esempi di applicazione:
Analisi del carrello della spesa: scoprire i prodotti che vengono acquistati frequentemente insieme.
Clustering genetico: raggruppamento di geni con modelli di espressione simili.
Analisi delle reti sociali: identificazione di comunità all'interno di grandi reti.
Rilevamento di anomalie: individuazione di transazioni fraudolente nel settore bancario.
Apprendimento semi-supervisionato
Forse conoscete il problema: avete molti dati, ma solo una piccola parte di essi è etichettata, e etichettare tutto completamente richiederebbe troppo tempo. La quantità di dati disponibili gioca un ruolo decisivo nell'efficienza dell'apprendimento semi-supervisionato, poiché l'obiettivo è ottenere il massimo beneficio possibile con risorse limitate. È proprio a questo che serve l'apprendimento semi-supervisionato.
Nell'apprendimento semi-supervisionato, i modelli di ML devono soddisfare determinati requisiti, ad esempio per quanto riguarda la capacità di gestire dati incompleti o eterogenei e di tenere conto dei requisiti specifici del settore.
In questo caso si utilizza un mix di entrambi i mondi:
In primo luogo, il modello apprende con i dati etichettati esistenti.
Poi utilizza questa conoscenza per classificare i dati non etichettati.
Se riconosce modelli con un alto grado di certezza, questi dati vengono "pseudo-etichettati" e inclusi nel set di addestramento.
I modelli di ML svolgono un ruolo centrale, in quanto sono in grado di riconoscere i modelli nei dati non etichettati e di classificarli in modo efficiente.
In questo modo, il set di dati cresce passo dopo passo e il modello diventa sempre più preciso, senza dover preparare manualmente tutti i dati.
Apprendimento con rinforzo
L'apprendimento per rinforzo funziona come l'apprendimento attraverso l'esperienza. L'algoritmo prova qualcosa, riceve un feedback - positivo o negativo - e ottimizza il suo comportamento. L'algoritmo esegue diverse azioni per ottenere il miglior risultato possibile. Nel processo di apprendimento, vengono prese continuamente decisioni per risolvere problemi complessi e l'algoritmo impara dai risultati delle sue azioni. In alcuni casi può essere necessario l'intervento umano, ad esempio per regolare i dati o ottimizzare il modello per risolvere problemi specifici. Migliora ad ogni esecuzione.
Cosa lo rende speciale: Il sistema non si limita a perseguire risultati a breve termine, ma lavora per raggiungere un obiettivo generale. Un esempio è un programma di scacchi. Può avere senso sacrificare temporaneamente dei pezzi per vincere la partita in un secondo momento. È proprio questo pensiero a lungo termine che l'apprendimento per rinforzo padroneggia particolarmente bene.
È adatto ovunque si debbano prendere decisioni complesse in ambienti dinamici, ad esempio nella robotica o nei sistemi autonomi.
Esempi di applicazione:
Videogiochi: l'intelligenza artificiale impara a giocare a videogiochi complessi e a ottenere prestazioni eccezionali.
Robotica: consentire ai robot di imparare compiti come camminare o afferrare oggetti.
Veicoli autonomi: sviluppo di sistemi per auto a guida autonoma in grado di prendere decisioni nel traffico reale.
Raccomandazioni personalizzate: adattare nel tempo i suggerimenti alle preferenze individuali degli utenti.

Algoritmi comuni nell'apprendimento automatico: una panoramica
Se volete iniziare un progetto di Machine Learning, vi renderete subito conto che esiste un'ampia scelta di algoritmi. Ognuno di essi ha determinati punti di forza ed è adatto a compiti diversi. Esiste un'ampia gamma di algoritmi di Machine Learning che possono essere utilizzati a seconda dell'applicazione. A seconda del compito, vengono utilizzati metodi e modelli diversi, specificamente adattati ai rispettivi requisiti. Machine Learning svolge un ruolo centrale e apre numerose possibilità per vari argomenti e aree di applicazione. I seguenti metodi sono tra i più utilizzati e vi forniranno una buona panoramica iniziale.
Reti neurali
Le reti neurali artificiali (RNA) sono modellate sulla struttura del cervello umano. Sono costituite da migliaia di nodi interconnessi (neuroni) organizzati in diversi strati:
Strato di ingresso: registra i dati grezzi (ad esempio i pixel di un'immagine).
Strati nascosti: è qui che avviene la vera e propria "intelligenza". Ogni strato filtra caratteristiche più complesse, da semplici linee a interi volti.
Livello di output: fornisce il risultato (ad esempio, "L'immagine mostra un gatto").
La particolarità: Questa struttura a strati consente alle reti neurali di elaborare dati non strutturati che sarebbero troppo impegnativi per gli algoritmi tradizionali. Più strati ha una rete, più relazioni complesse comprende: questo è noto come apprendimento profondo.
Aree di applicazione:
Visione artificiale: riconoscimento facciale o analisi di immagini mediche.
NLP (Natural Language Processing): Strumenti di traduzione e chatbot come ChatGPT.
IA generativa: creazione di immagini, musica o testi realistici.
Regressione lineare
La regressione lineare è uno degli approcci più semplici e affidabili quando si tratta di prevedere valori numerici.
Ad esempio, si può utilizzare per stimare i prezzi degli immobili in base ai dati storici di una zona specifica. L'algoritmo cerca una relazione lineare tra vari fattori e la utilizza per creare previsioni. Il metodo segue una regola matematica chiaramente definita che specifica come le singole variabili di influenza vengono combinate per creare una previsione.
Regressione logistica
Anche la regressione logistica è uno dei metodi classici dell'apprendimento supervisionato. Fa previsioni per categorie, cioè risposte come "sì" o "no".
Le aree di applicazione tipiche sono il rilevamento dello spam, i controlli di qualità o tutte le situazioni in cui i dati devono essere classificati in classi ben definite.
Raggruppamento
Il clustering è una tecnica di apprendimento non supervisionato. L'algoritmo cerca autonomamente modelli e forma gruppi (cluster) senza che l'utente gli fornisca istruzioni preliminari.
Questo aiuta a riconoscere strutture o a individuare punti di dati insoliti, cose che spesso sfuggono all'occhio umano. Il clustering è spesso utilizzato nell'analisi dei dati e in particolare nella segmentazione dei clienti.
Alberi decisionali
Come suggerisce il nome, un albero decisionale funziona con una serie di decisioni successive che si diramano come rami di un albero.
È in grado di prevedere valori numerici e di categorizzare i dati. Questo è un grande vantaggio rispetto alle reti neurali: Gli alberi decisionali sono facili da capire e da spiegare. Ciò significa che è possibile vedere chiaramente perché il modello è arrivato a un determinato risultato.
Foreste casuali
Una foresta casuale è una "squadra" di molti alberi decisionali, per così dire. Ogni albero fa la sua previsione e alla fine si ottiene un giudizio complessivo da tutti i risultati.
Questa combinazione migliora l'accuratezza e riduce il rischio che un singolo albero prenda la decisione sbagliata.

Quali sono le aree di applicazione dell'apprendimento automatico?
L'apprendimento automatico è estremamente versatile e viene utilizzato in molti settori e aree della vita. A seconda dell'obiettivo, vengono utilizzati metodi e algoritmi diversi. Ecco una panoramica delle aree più importanti:
1. marketing e vendite
Nel marketing, Machine Learning aiuta a comprendere meglio i clienti e a creare offerte personalizzate. Gli algoritmi analizzano il comportamento d'acquisto, gli interessi e le preferenze per creare raccomandazioni adeguate o campagne mirate. Sulle piattaforme di shopping online, ad esempio, si ricevono suggerimenti del tipo "I clienti che hanno acquistato questo prodotto hanno acquistato anche ...". Per le aziende, questo significa maggiore soddisfazione dei clienti e misure di marketing più efficaci.
Esempi
Motori di raccomandazione: suggerimenti del tipo "I clienti che hanno acquistato questo prodotto hanno acquistato anche ...".
Strategie di cross-selling: consigli personalizzati sui prodotti durante il processo di ordinazione.
2. servizio clienti
I chatbot e gli assistenti digitali, che potreste già utilizzare sui siti web o nelle app, spesso funzionano con Machine Learning. Imparano dalle richieste precedenti, possono rispondere autonomamente alle domande di routine e inoltrare le richieste più complesse all'uomo. In questo modo si risparmia tempo, si riducono i tempi di attesa per i clienti e si alleggerisce il personale.
Esempi
Chatbot e assistenti virtuali: Risposta a domande frequenti, consulenza personalizzata, inoltro di richieste complesse a dipendenti umani.
Riconoscimento vocale/assistenti vocali: Interazione automatizzata tramite dispositivi come Siri o bot vocali
3. finanza e banche
Machine Learning è diventato indispensabile nel mondo della finanza. Gli algoritmi riconoscono le transazioni insolite e aiutano quindi a individuare tempestivamente i tentativi di frode. Allo stesso tempo, supportano le analisi del rischio, ad esempio per le richieste di prestito, e migliorano la previsione dei prezzi delle azioni o delle tendenze del mercato.
Esempi
Rilevamento delle frodi: analisi delle transazioni, individuazione di attività sospette.
Trading azionario automatizzato: trading ad alta frequenza e ottimizzazione del portafoglio
4. produzione e logistica
Nell'industria, Machine Learning garantisce processi più efficienti. Gli algoritmi possono prevedere i requisiti di manutenzione delle macchine, ottimizzare i processi produttivi e pianificare le catene di fornitura in modo più intelligente. Ciò consente di tagliare i costi, ridurre i tempi di inattività e utilizzare meglio le risorse.
Esempi
Automazione robotica dei processi (RPA): Automazione di attività manuali ricorrenti
Manutenzione predittiva: previsione dei requisiti di manutenzione per le macchine
Ottimizzazione delle catene di fornitura: pianificazione e utilizzo più efficiente delle risorse
5. assistenza sanitaria
Machine Learning ha un enorme potenziale anche nel settore medico. I sistemi analizzano le immagini mediche, assistono le diagnosi o riconoscono gli schemi nei dati dei pazienti per identificare le malattie in una fase iniziale. Ciò consente ai medici di prendere decisioni più rapidamente e di migliorare le cure.
Esempi
Visione artificiale per immagini mediche: Supporto alle diagnosi, riconoscimento di modelli nei dati dei pazienti
6 Vita quotidiana e intrattenimento
Machine Learning si incontra anche nella vita quotidiana, spesso senza rendersene conto: Raccomandazioni musicali e video dai servizi di streaming, riconoscimento facciale negli smartphone, applicazioni per case intelligenti e sistemi di navigazione: tutti si basano su algoritmi che imparano dai dati per offrire servizi migliori e più personalizzati.
Esempi
Raccomandazioni di streaming: Raccomandazioni di musica e video su piattaforme come Spotify o Netflix.
Riconoscimento facciale e applicazioni per la casa intelligente: Smartphone, sensori per porte, dispositivi intelligenti
Sistemi di navigazione: ottimizzazione del percorso e previsioni sul traffico

Conclusione: Machine Learning - il vostro ingresso nel futuro
Machine Learning non è più un argomento del futuro: fa parte della nostra vita quotidiana e sta cambiando il modo in cui le aziende lavorano, offrono prodotti e prendono decisioni. Dai consigli personalizzati sui prodotti all'assistenza automatizzata ai clienti, fino al rilevamento delle frodi e alle diagnosi mediche: le applicazioni potenziali sono diverse e vanno ben oltre gli esempi più noti.
Per voi o per la vostra azienda, questo significa che chiunque abbia familiarità con Machine Learning può organizzare i processi in modo più efficiente, prendere decisioni migliori e sviluppare soluzioni innovative. Non è necessario essere subito un esperto. È possibile imparare le basi passo dopo passo, comprendere i vari algoritmi e sperimentare applicazioni pratiche.
La FIDAcademy offre esattamente i corsi giusti per questo. Che vogliate comprendere le basi del machine learning, familiarizzare con il deep learning o implementare applicazioni specifiche come i motori di raccomandazione, i chatbot o la manutenzione predittiva, all'Accademia troverete corsi di formazione pratici che vi aiuteranno a utilizzare il machine learning in modo mirato. Questo vi permetterà di entrare nel mondo dell'intelligenza artificiale in modo sicuro e strutturato e di sfruttare al meglio le opportunità offerte da questa tecnologia.
FAQ: Domande frequenti sull'apprendimento automatico
L'apprendimento automatico è una branca dell'intelligenza artificiale. I computer imparano dai dati e migliorano con ogni nuova esperienza, proprio come gli esseri umani. L'obiettivo è riconoscere schemi, fare previsioni o automatizzare le decisioni senza che ogni regola debba essere programmata in precedenza da un essere umano.
L'intelligenza artificiale (AI) è il termine generale che descrive qualsiasi tecnologia che imita l'intelligenza umana.
L'apprendimento automatico ne fa parte: è il metodo con cui i sistemi imparano in modo indipendente dai dati.
In breve: il ML è una sottocategoria dell'IA, ma non tutta l'IA utilizza l'apprendimento automatico.
Sì, ma con una piccola novità:
ChatGPT si basa su un modello avanzato di apprendimento automatico, il cosiddetto Large Language Model (LLM). Questo modello è stato addestrato con enormi quantità di testo per riconoscere gli schemi del linguaggio e formulare risposte comprensibili.
Si può quindi pensare a ChatGPT come a un'applicazione particolarmente potente dell'apprendimento automatico.
Ci sono molti esempi che si usano ogni giorno senza pensarci consapevolmente. Un esempio tipico: le raccomandazioni di Netflix, Amazon o Spotify.
Questi servizi analizzano il vostro comportamento - ad esempio ciò che avete acquistato, ascoltato o guardato - e vi suggeriscono prodotti, film o canzoni adatti.
Anche i filtri antispam, i sistemi di navigazione o l'etichettatura delle foto negli smartphone ne fanno parte.
Non necessariamente. È possibile comprendere le basi anche senza esperienza di programmazione. Molti strumenti consentono di iniziare a lavorare con estrema facilità. Tuttavia, se si desidera sviluppare i propri modelli, è necessaria una certa programmazione, di solito in Python.
Le aziende utilizzano il ML ad esempio per
pubblicità personalizzata e raccomandazioni di prodotti
assistenza clienti automatizzata
il rilevamento delle frodi
ottimizzazione della produzione e manutenzione predittiva
analisi del rischio
automazione dei processi
Le possibilità sono in costante crescita.
Assolutamente sì, ed è più facile di quanto molti pensino. Con delle buone istruzioni, potrete capire rapidamente le basi e provare i vostri primi modelli. Alla FIDAcademy troverete corsi pratici che vi guideranno passo dopo passo, da principianti a professionisti.



