
Was ist Machine Learning (maschinelles Lernen) und wie kann es eingesetzt werden?
Vielleicht kennst Du dieses Gefühl: Du öffnest Netflix und findest sofort eine Serie, die genau Deinen Geschmack trifft. Oder Dein Smartphone sortiert Deine Fotos so clever, dass Du bestimmte Momente mit nur einem Fingertipp wiederfindest. Du denkst Dir vielleicht: „Ganz schön praktisch.“ Und genau dahinter steckt Machine Learning. Machine Learning hat sich von einem Science-Fiction-Konzept zu einem zentralen Bestandteil der heutigen Informationsverarbeitung entwickelt.
Maschinelles Lernen ist längst kein Zukunftsszenario mehr, sondern begleitet Dich jeden Tag – ganz unauffällig, aber unglaublich wirkungsvoll. Es hilft Dir, Zeit zu sparen, bessere Entscheidungen zu treffen und Informationen zu bekommen, die zu Deinen Bedürfnissen passen. Und je mehr Du Dich damit beschäftigst, desto klarer wird Dir, wie stark diese Technologie unsere Welt verändert.
Was Machine Learning so besonders macht? Computer lernen Dinge, ohne dass ihnen jeder einzelne Schritt vorgegeben werden muss. Die Algorithmen laufen dabei auf Computern, verarbeiten große Datenmengen und automatisieren Aufgaben, indem sie Muster erkennen und Entscheidungen treffen. Sie erkennen Muster, treffen Vorhersagen und beschleunigen so Geschäftsprozesse. Und das eröffnet nicht nur Dir im Alltag neue Möglichkeiten, sondern vor allem Unternehmen – egal ob groß oder klein. Prozesse laufen reibungsloser, Daten werden wertvoller genutzt und Aufgaben, die früher viel Zeit gefressen haben, erledigt ein System heute fast nebenbei – wobei die genaue Aufgabenstellung entscheidend dafür ist, welches Machine Learning-Modell eingesetzt wird.
Begleite uns in diesem Beitrag auf eine Reise hinter die Kulissen künstlicher Intelligenz.
Was bedeutet Machine Learning eigentlich?
Wenn Du Dich schon einmal gefragt hast, wie Computer es schaffen, aus Erfahrungen klüger zu werden, dann bist Du beim Thema Machine Learning genau richtig. Maschinelles Lernen (kurz ML) ist ein Teilbereich der künstlichen Intelligenz. Diese Begriffe werden häufig gemeinsam verwendet, daher ist es wichtig, die einzelnen Begriffe wie Machine Learning, Deep Learning und KI voneinander abzugrenzen. Dabei geht es darum, Systeme zu entwickeln, die aus Daten lernen, Muster erkennen und sich mit der Zeit selbst verbessern, ohne dass jemand jeden einzelnen Schritt programmieren muss.
Künstliche Intelligenz ist damit der übergeordnete Begriff. Er beschreibt Technologien, die versuchen, menschliches Denken nachzubilden – egal ob durch fest definierte Regeln oder durch lernende Algorithmen. Deshalb werden KI und Machine Learning oft in einem Satz genannt, auch wenn beides nicht dasselbe ist. Die Definition von Machine Learning bildet dabei eine wichtige Grundlage, um die Begriffe und Zusammenhänge innerhalb der künstlichen Intelligenz zu verstehen.
Du kannst es Dir so merken: Machine Learning ist ein spezieller Ansatz innerhalb der KI – aber nicht jede KI arbeitet mit Machine Learning.

Machine Learning vs. Deep Learning wo liegt der Unterschied?
Vielleicht hast Du schon bemerkt, dass die Begriffe Machine Learning und Deep Learning im Alltag oft gleichbedeutend verwendet werden. Kein Wunder, denn beide gehören zur künstlichen Intelligenz. Trotzdem gibt es wichtige Unterschiede, die Dir helfen, die Technologie besser einzuordnen.
Grundsätzlich kannst Du Dir die Beziehung so vorstellen: Machine Learning ist der große Oberbegriff – darin befinden sich die neuronalen Netze – und Deep Learning ist wiederum ein spezieller Bereich dieser neuronalen Netze. Deep Learning stellt dabei ein Teilgebiet des Machine Learnings dar, das sich durch besonders komplexe Strukturen und große Datenmengen auszeichnet.

Wie funktioniert Machine Learning?
Maschinelles Lernen funktioniert im Grunde ähnlich wie Dein eigener Lernprozess: Durch Wiederholen, Ausprobieren und Feedback wird das System mit der Zeit immer besser. Am Anfang bekommt der Algorithmus noch Unterstützung durch den Menschen, bzw. durch einen sauber kuratierten Datensatz – später trifft er Entscheidungen selbstständig. Der Weg dahin lässt sich gut in ein paar Schritte einteilen.
Im sogenannten Machine Learning Prozess werden die einzelnen Phasen – von der Datensammlung über die Modellentwicklung und das Training bis hin zur Optimierung und Implementierung – systematisch durchlaufen. Der Machine Learning Prozess erfordert dabei eine große Menge hochwertiger Daten, um präzise Ergebnisse zu erzielen.

1. Training: Das System lernt aus Beispielen
Zuerst fütterst Du das Modell mit einem Trainingsdatensatz. Große Datensätze sind dabei entscheidend, da sie die Grundlage für das Training und die Optimierung von Machine-Learning-Modellen bilden. Diese Daten stammen von Dir oder Deinem Team und helfen dem Algorithmus, Muster, Zusammenhänge und Regeln zu erkennen. Je mehr und je vielfältiger die Beispiele sind, desto besser kann das System später arbeiten.
Die Qualität und Menge der Datensätze sind dabei ausschlaggebend für die Leistungsfähigkeit des Modells. Einzelne Datenpunkte werden genutzt, um das Modell gezielt zu verfeinern und präzisere Vorhersagen zu ermöglichen. Beispieldaten spielen eine zentrale Rolle beim Training verschiedener Lernverfahren, da sie dem Modell helfen, relevante Muster zu erkennen. Die Datenmenge beeinflusst maßgeblich die Genauigkeit und das Training des Modells. Im Machine Learning werden oft große Mengen an Daten verarbeitet, um die Modelle kontinuierlich zu verbessern und automatisierte Prozesse zu ermöglichen.
Du kannst Dir diesen Schritt wie „Üben“ vorstellen: Mit jeder Durchlauf verbessert sich die Qualität der Ergebnisse.
2. Iteratives Lernen: Schritt für Schritt zur besseren Genauigkeit
Machine Learning ist ein fortlaufender Prozess. Das Modell wiederholt seine Aufgaben so lange, bis es eine bestimmte Genauigkeit erreicht. In dieser Phase wird fortlaufend die Leistungsfähigkeit des Systems kontrolliert. Wenn nötig, kannst Du eingreifen, nachjustieren oder zusätzliche Daten bereitstellen, um die Ergebnisse weiter zu verbessern. Menschliche Eingriffe sind dabei entscheidend, um den Trainingsprozess zu überwachen und gezielt zu optimieren, sodass die Qualität und Genauigkeit der Modelle kontinuierlich sichergestellt werden.
3. Fehler erkennen und korrigieren
Macht das Modell eine falsche Vorhersage, wird dieser Fehler genutzt, um das System weiter anzupassen. Die internen Parameter verändern sich – so passt das Modell seine „Denkweise“ an.
Mit jeder Korrektur wird es ein Stück präziser und lernt, die richtigen Muster zuverlässig zu erkennen, wobei es zunehmend auch komplexe Muster zu erkennen vermag.
4. Einsatz: Das Modell arbeitet selbstständig
Sobald die Genauigkeit hoch genug ist, kannst Du das Modell in der Praxis einsetzen. Das ML Modell analysiert dabei neue Daten, erkennt Muster und unterstützt so fundierte Entscheidungen in den jeweiligen Geschäftsprozessen. Jetzt kann es mit neuen, bisher unbekannten Daten umgehen und eigenständig Vorhersagen treffen oder Entscheidungen unterstützen. Das System nutzt sein gelerntes Wissen, um in Echtzeit zu reagieren und immer bessere Ergebnisse zu liefern.
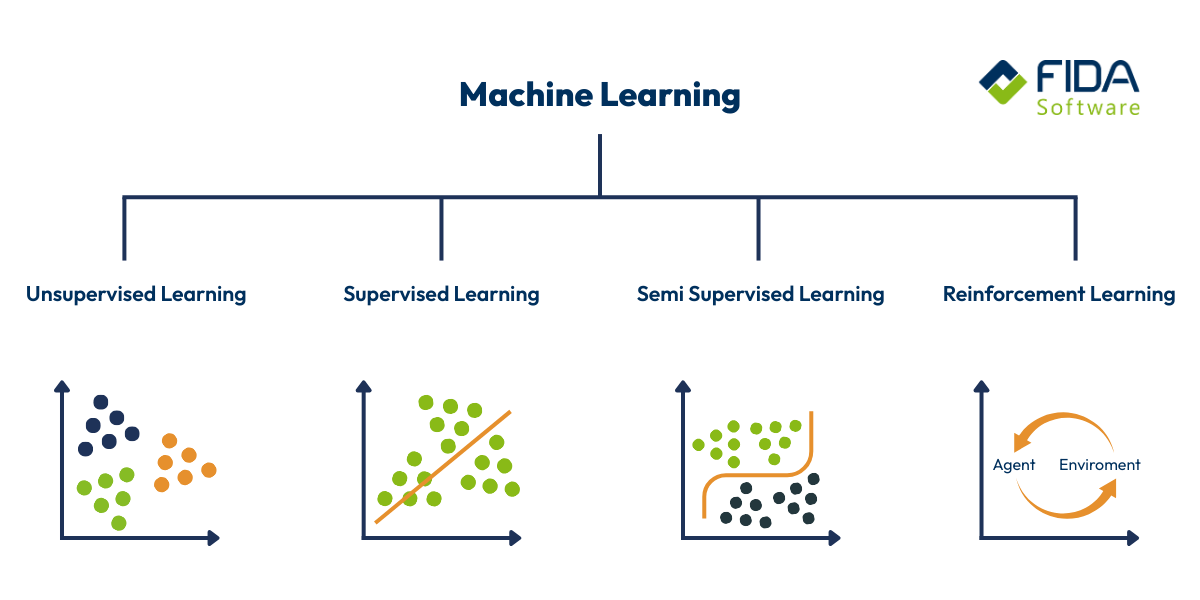
Welche Arten des maschinellen Lernens gibt es?
Machine Learning ist nicht gleich Machine Learning. Es gibt verschiedene Ansätze, die je nach Ziel, Datenlage und Aufwand ganz unterschiedliche Stärken haben. Diese Ansätze können verschiedene Formen des maschinellen Lernens annehmen, die jeweils spezifische Einsatzmöglichkeiten und Vorteile für unterschiedliche Branchen bieten. Damit Du ein besseres Gefühl dafür bekommst, welcher Ansatz wofür geeignet ist, schauen wir uns die vier wichtigsten Arten einmal genauer an.
Überwachtes Lernen (Supervised Learning)
Beim überwachten Lernen bekommt der Algorithmus eine Art „Lernhilfe“: Die Daten, mit denen Du ihn fütterst, sind bereits beschriftet. Um das optimale Modell für die jeweilige Aufgabe zu entwickeln, werden verschiedene Lernverfahren und Machine Learning Algorithmen eingesetzt.
Ein typisches Beispiel ist ein Spam-Filter. Dort lernt das Modell anhand vieler E-Mails, die bereits als „Spam“ oder „Nicht-Spam“ markiert wurden, wobei das Modell darauf trainiert wird, möglichst präzise Vorhersagen zu treffen. Das Modell spielt eine zentrale Rolle bei der Analyse und Kategorisierung der Daten, indem es Muster erkennt und diese für zukünftige Entscheidungen nutzt.
Wichtig ist: Die Trainingsdaten müssen repräsentativ für die echte Welt sein. Wenn die Daten nur idealisierte Beispiele enthalten und keine natürliche Varianz zeigen, lernt das Modell die Realität nicht umfassend genug. Zudem besteht bei zu komplexen Modellen die Gefahr des Overfittings: Das Modell lernt dann die Trainingsdaten quasi auswendig, kann das Wissen aber nicht auf neue, unbekannte E-Mails anwenden.
Anwendungsbeispiele:
E-Mail-Filterung : Klassifizierung von E-Mails als Spam oder Nicht-Spam.
Medizinische Diagnostik: Vorhersage von Krankheiten anhand von Symptomen.
Finanzanalyse : Prognose von Aktienkursen.
Bilderkennung : Identifizierung von Objekten in Bildern.
Unüberwachtes Lernen (Unsupervised Learning)
Beim unüberwachten Lernen ist der Algorithmus komplett auf sich gestellt. Du gibst ihm unbeschriftete Daten – ohne richtige oder falsche Antworten – und er versucht selbst, Muster und Zusammenhänge zu erkennen. Das Verständnis der Zusammenhänge zwischen Variablen ist dabei entscheidend, um relevante Informationen aus den Daten zu extrahieren.
Verschiedene Modelle und Methoden werden eingesetzt, um aus unstrukturierten Daten neue Erkenntnisse zu gewinnen und Zusammenhänge sichtbar zu machen. Die praktische Anwendung des unüberwachten Lernens zeigt sich beispielsweise in Unternehmen, die damit Prozesse optimieren oder im Alltag, etwa bei der automatischen Sortierung von Fotos.
Der Ansatz eignet sich besonders gut, um Gruppen zu bilden (Cluster) oder ungewöhnliche Muster zu identifizieren (Anomalien). Empfehlungsfunktionen in Shops arbeiten häufig damit. Sie erkennen zum Beispiel: „Kunden, die dieses Produkt gekauft haben, interessieren sich auch für …“
Auch für die Betrugserkennung ist unüberwachtes Lernen sehr wertvoll. Entdeckt das System Muster, die stark vom Normalfall abweichen, schlägt es Alarm.
Anwendungsbeispiele:
Warenkorbanalyse : Produkte entdecken, die häufig zusammen gekauft werden.
Genetisches Clustering : Gruppierung von Genen mit ähnlichen Expressionsmustern.
Soziale Netzwerkanalyse : Identifizierung von Gemeinschaften innerhalb großer Netzwerke.
Anomalieerkennung : Aufspüren betrügerischer Transaktionen im Bankwesen.
Teilüberwachtes Lernen (Semi-Supervised Learning)
Vielleicht kennst Du das Problem: Du hast viele Daten, aber nur ein kleiner Teil davon ist beschriftet – und alles vollständig zu kennzeichnen wäre viel zu aufwendig. Die verfügbare Datenmenge spielt dabei eine entscheidende Rolle für die Effizienz des teilüberwachten Lernens, da mit begrenzten Ressourcen ein möglichst großer Nutzen erzielt werden soll. Genau dafür gibt es teilüberwachtes Lernen.
Beim teilüberwachten Lernen müssen bestimmte Anforderungen an die ML-Modelle erfüllt werden, etwa im Hinblick auf die Fähigkeit, mit unvollständigen oder heterogenen Daten umzugehen und branchenspezifische Voraussetzungen zu berücksichtigen.
Hier wird ein Mix aus beiden Welten genutzt:
Zuerst lernt das Modell mit den vorhandenen beschrifteten Daten.
Danach nutzt es dieses Wissen, um unbeschriftete Daten einzuordnen.
Erkennt es Muster mit hoher Sicherheit, werden diese Daten „pseudo-beschriftet“ und in den Trainingssatz aufgenommen.
ML-Modelle spielen dabei eine zentrale Rolle, da sie in der Lage sind, Muster in unbeschrifteten Daten zu erkennen und diese effizient zu klassifizieren.
So wächst der Datensatz Schritt für Schritt und das Modell wird immer präziser – ohne dass Du alle Daten manuell vorbereiten musst.
Verstärkendes Lernen (Reinforcement Learning)
Reinforcement Learning funktioniert wie Lernen durch Erfahrung. Der Algorithmus probiert etwas aus, bekommt Feedback – positiv oder negativ – und optimiert sein Verhalten. Dabei führt der Algorithmus verschiedene Aktionen aus, um das bestmögliche Ergebnis zu erzielen. Im Lernprozess werden kontinuierlich Entscheidungen getroffen, um komplexe Probleme zu lösen, wobei der Algorithmus aus den Ergebnissen seiner Aktionen lernt. In manchen Fällen kann ein menschlicher Eingriff erforderlich sein, etwa zur Anpassung der Daten oder Optimierung des Modells, um spezifische Probleme zu adressieren. Mit jedem Durchlauf wird er besser.
Das Besondere: Das System verfolgt nicht nur kurzfristige Ergebnisse, sondern arbeitet auf ein übergeordnetes Ziel hin. Ein Beispiel ist ein Schachprogramm. Es kann sinnvoll sein, vorübergehend Figuren zu opfern, um später das Spiel zu gewinnen. Genau dieses langfristige Denken beherrscht Reinforcement Learning besonders gut.
Es eignet sich überall dort, wo komplexe Entscheidungen in dynamischen Umgebungen getroffen werden müssen – zum Beispiel in der Robotik oder bei autonomen Systemen.
Anwendungsbeispiele:
Videospiele : Künstliche Intelligenz lernen, komplexe Videospiele zu spielen und darin hervorragende Leistungen zu erzielen.
Robotik : Robotern das Erlernen von Aufgaben wie Gehen oder Greifen nach Objekten ermöglichen.
Autonome Fahrzeuge : Entwicklung von Systemen für selbstfahrende Autos, die im realen Straßenverkehr Entscheidungen treffen können.
Personalisierte Empfehlungen : Wir passen die Vorschläge im Laufe der Zeit an die individuellen Vorlieben der Nutzer an.

Gängige Algorithmen im Machine Learning – ein Überblick
Wenn Du ein Machine-Learning-Projekt starten möchtest, wirst Du schnell merken, dass es eine große Auswahl an Algorithmen gibt. Jeder von ihnen hat bestimmte Stärken und eignet sich für unterschiedliche Aufgaben. Es existiert eine Vielzahl von Machine Learning Algorithmen, die je nach Anwendungsfall eingesetzt werden können. Je nach Aufgabenstellung kommen unterschiedliche Methoden und Modelle zum Einsatz, die speziell auf die jeweiligen Anforderungen zugeschnitten sind. Das maschinelle Lernen spielt dabei eine zentrale Rolle und eröffnet zahlreiche Möglichkeiten für verschiedene Themen und Anwendungsgebiete. Die folgenden Methoden gehören zu den am häufigsten genutzten – und geben Dir einen guten ersten Überblick.
Neuronale Netze
Künstliche Neuronale Netze (KNN) sind der Struktur des menschlichen Gehirns nachempfunden. Sie bestehen aus Tausenden miteinander verknüpften Knoten (Neuronen), die in mehreren Schichten organisiert sind:
Input-Layer: Nimmt die Rohdaten auf (z. B. die Pixel eines Bildes).
Hidden-Layers: Hier findet die eigentliche „Intelligenz“ statt. Jede Schicht filtert komplexere Merkmale heraus – von einfachen Linien bis hin zu ganzen Gesichtern.
Output-Layer: Liefert das Ergebnis (z. B. „Das Bild zeigt eine Katze“).
Das Besondere: Durch diese Schichtstruktur können neuronale Netze unstrukturierte Daten verarbeiten, mit denen klassische Algorithmen überfordert sind. Je mehr Schichten ein Netz hat, desto komplexere Zusammenhänge versteht es – man spricht dann von Deep Learning.
Einsatzgebiete:
Computer Vision: Gesichtserkennung oder medizinische Bildanalyse.
NLP (Natural Language Processing): Übersetzungstools und Chatbots wie ChatGPT.
Generative KI: Erstellung von realistischen Bildern, Musik oder Texten.
Lineare Regression
Die lineare Regression ist einer der einfachsten und gleichzeitig zuverlässigsten Ansätze, wenn es darum geht, numerische Werte vorherzusagen.
Ein Beispiel: Du könntest damit Immobilienpreise anhand historischer Daten für ein bestimmtes Gebiet schätzen. Der Algorithmus sucht nach einer linearen Beziehung zwischen verschiedenen Faktoren – und nutzt diese, um Prognosen zu erstellen. Dabei folgt die Methode einer klar definierten mathematischen Regel, die festlegt, wie die einzelnen Einflussgrößen zur Vorhersage kombiniert werden.
Logistische Regression
Auch die logistische Regression gehört zu den klassischen Methoden im überwachten Lernen. Sie trifft Vorhersagen für Kategorien – also Antworten wie „Ja“ oder „Nein“.
Typische Einsatzbereiche sind Spam-Erkennung, Qualitätsprüfungen oder alle Situationen, in denen es darum geht, Daten in klar abgegrenzte Klassen einzuordnen.
Clustering
Clustering ist eine Technik aus dem unüberwachten Lernen. Der Algorithmus sucht selbstständig nach Mustern und bildet Gruppen (Cluster), ohne dass Du ihm vorher Vorgaben machst.
Das hilft dabei, Strukturen zu erkennen oder ungewöhnliche Datenpunkte aufzuspüren – Dinge, die dem menschlichen Auge oft entgehen. Besonders in der Datenanalyse oder bei Kunden-Segmentierungen wird Clustering häufig genutzt.
Entscheidungsbäume
Ein Entscheidungsbaum arbeitet – wie der Name schon sagt – mit einer Reihe von aufeinander aufbauenden Entscheidungen, die sich wie Äste eines Baumes verzweigen.
Er kann sowohl numerische Werte vorhersagen als auch Daten in Kategorien einordnen. Ein großer Vorteil gegenüber neuronalen Netzen: Entscheidungsbäume lassen sich leicht nachvollziehen und erklären. Du kannst also klar sehen, warum das Modell zu einem bestimmten Ergebnis gekommen ist.
Random Forests
Ein Random Forest ist sozusagen eine „Mannschaft“ aus vielen Entscheidungsbäumen. Jeder Baum trifft eine eigene Vorhersage – und am Ende wird aus allen Ergebnissen ein Gesamturteil gebildet.
Durch diese Kombination wird die Genauigkeit verbessert und das Risiko verringert, dass ein einzelner Baum falsche Entscheidungen trifft.

Welche Einsatzbereiche von Machine Learning gibt es?
Machine Learning ist extrem vielseitig und wird in vielen Branchen und Lebensbereichen eingesetzt. Je nach Zielsetzung kommen unterschiedliche Methoden und Algorithmen zum Einsatz. Hier sind die wichtigsten Bereiche im Überblick:
1. Marketing und Vertrieb
Im Marketing hilft Machine Learning dabei, Kunden besser zu verstehen und personalisierte Angebote zu erstellen. Algorithmen analysieren Kaufverhalten, Interessen und Vorlieben, um passende Empfehlungen oder gezielte Kampagnen zu erstellen. So bekommst Du zum Beispiel auf Online-Shopping-Plattformen Vorschläge wie „Kunden, die dieses Produkt gekauft haben, kauften auch …“. Für Unternehmen bedeutet das: höhere Kundenzufriedenheit und effektivere Marketingmaßnahmen.
Beispiele
Recommendation-Engines: Vorschläge wie „Kunden, die dieses Produkt gekauft haben, kauften auch …“
Cross-Selling-Strategien: Personalisierte Produktempfehlungen während des Bestellvorgangs
2. Kundenservice
Chatbots und digitale Assistenten, die Du vielleicht schon auf Websites oder in Apps nutzt, arbeiten häufig mit Machine Learning. Sie lernen aus bisherigen Anfragen, können Routinefragen selbstständig beantworten und leiten komplexere Anliegen an Menschen weiter. Das spart Zeit, reduziert Wartezeiten für Kunden und entlastet Mitarbeiter.
Beispiele
Chatbots und virtuelle Assistenten: Beantwortung von FAQs, personalisierte Beratung, Weiterleitung komplexer Anfragen an menschliche Mitarbeiter
Spracherkennung / Sprachassistenten: Automatisierte Interaktion über Geräte wie Siri oder Sprachbots
3. Finanzen und Banking
Machine Learning ist in der Finanzwelt unverzichtbar geworden. Algorithmen erkennen ungewöhnliche Transaktionen und helfen so, Betrugsversuche frühzeitig zu entdecken. Gleichzeitig unterstützen sie bei der Risikoanalyse, etwa bei Kreditanträgen, und verbessern die Vorhersage von Aktienkursen oder Markttrends.
Beispiele
Betrugserkennung: Analyse von Transaktionen, Erkennung verdächtiger Aktivitäten
Automatisierter Aktienhandel: Hochfrequenzhandel und Portfolio-Optimierung
4. Produktion und Logistik
In der Industrie sorgt Machine Learning für effizientere Abläufe. Algorithmen können Wartungsbedarfe von Maschinen vorhersagen, Produktionsprozesse optimieren und Lieferketten smarter planen. So lassen sich Kosten senken, Ausfallzeiten reduzieren und Ressourcen besser nutzen.
Beispiele
Robotic Process Automation (RPA): Automatisierung wiederkehrender manueller Aufgaben
Predictive Maintenance: Vorhersage von Wartungsbedarfen bei Maschinen
Optimierung von Lieferketten: Effizientere Planung und Ressourcennutzung
5. Gesundheitswesen
Auch im medizinischen Bereich hat Machine Learning enormes Potenzial. Systeme analysieren medizinische Bilder, unterstützen bei Diagnosen oder erkennen Muster in Patientendaten, um Krankheiten frühzeitig zu identifizieren. So können Ärzte schneller Entscheidungen treffen und die Versorgung verbessern.
Beispiele
Computer Vision für medizinische Bilder: Unterstützung bei Diagnosen, Mustererkennung in Patientendaten
6. Alltag und Unterhaltung
Du begegnest Machine Learning auch im Alltag, oft ohne es zu merken: Musik- und Videoempfehlungen bei Streaming-Diensten, Gesichtserkennung in Smartphones, Smart-Home-Anwendungen oder Navigationssysteme – all das basiert auf Algorithmen, die aus Daten lernen, um Dir bessere und individuellere Dienste zu bieten.
Beispiele
Streaming-Empfehlungen: Musik- und Videoempfehlungen auf Plattformen wie Spotify oder Netflix
Gesichtserkennung und Smart-Home-Anwendungen: Smartphones, Türsensoren, intelligente Geräte
Navigationssysteme: Routenoptimierung und Verkehrsprognosen

Fazit: Machine Learning – Dein Einstieg in die Zukunft
Machine Learning ist längst kein Zukunftsthema mehr – es ist Teil unseres Alltags und verändert, wie Unternehmen arbeiten, Produkte anbieten und Entscheidungen treffen. Von personalisierten Produktempfehlungen über automatisierte Kundenbetreuung bis hin zu Betrugserkennung und medizinischen Diagnosen: Die Einsatzmöglichkeiten sind vielfältig und reichen weit über die bekannten Beispiele hinaus.
Für Dich persönlich oder für Dein Unternehmen bedeutet das: Wer sich mit Machine Learning auskennt, kann Prozesse effizienter gestalten, bessere Entscheidungen treffen und innovative Lösungen entwickeln. Dabei ist es gar nicht nötig, sofort ein Experte zu sein. Schritt für Schritt lassen sich die Grundlagen lernen, die verschiedenen Algorithmen verstehen und praxisnahe Anwendungen ausprobieren.
Die FIDAcademy bietet genau dafür die passenden Kurse an. Egal, ob Du die Grundlagen des maschinellen Lernens verstehen, Deep Learning kennenlernen oder konkrete Anwendungen wie Recommendation-Engines, Chatbots oder Predictive Maintenance umsetzen möchtest – in der Academy findest Du praxisnahe Trainings, die Dir helfen, Machine Learning gezielt einzusetzen. So kannst Du sicher und strukturiert in die Welt der künstlichen Intelligenz starten und die Chancen dieser Technologie optimal nutzen.
FAQ: Häufige Fragen rund um Machine Learning
Machine Learning ist ein Teilbereich der künstlichen Intelligenz. Dabei lernen Computer aus Daten und verbessern sich mit jeder neuen Erfahrung – ganz ähnlich wie wir Menschen. Das Ziel: Muster erkennen, Vorhersagen treffen oder Entscheidungen automatisieren, ohne dass jede Regel vorher von einem Menschen programmiert werden muss.
Künstliche Intelligenz (AI) ist der übergeordnete Begriff und beschreibt jede Technologie, die menschliche Intelligenz nachahmt.
Machine Learning ist ein Teil davon – es ist die Methode, mit der Systeme selbstständig aus Daten lernen.
Kurz gesagt: ML ist eine Unterkategorie von AI, aber nicht jede AI nutzt Machine Learning.
Ja – aber mit einer kleinen Besonderheit:
ChatGPT basiert auf einem fortschrittlichen Machine-Learning-Modell, das sogenannte Large Language Model (LLM). Dieses wurde mit riesigen Mengen an Text trainiert, um Muster in Sprache zu erkennen und verständliche Antworten zu formulieren.
Du kannst Dir ChatGPT also als eine besonders mächtige Anwendung von Machine Learning vorstellen.
Es gibt viele Beispiele, die Du täglich nutzt, ohne bewusst daran zu denken. Ein typisches Beispiel: Empfehlungen bei Netflix, Amazon oder Spotify.
Diese Dienste analysieren Dein Verhalten – etwa, was Du gekauft, gehört oder angesehen hast – und schlagen Dir passende Produkte, Filme oder Songs vor.
Auch Spamfilter, Navigationssysteme oder Foto-Tagging in Smartphones gehören dazu.
Nicht unbedingt. Die Grundlagen kannst Du auch ohne Programmiererfahrung verstehen. Viele Tools machen den Einstieg inzwischen sehr einfach. Möchtest Du allerdings eigene Modelle entwickeln, ist etwas Programmierung – meist in Python – notwendig.
Unternehmen nutzen ML zum Beispiel für:
personalisierte Werbung und Produktempfehlungen
automatisierten Kundenservice
Betrugserkennung
Produktionsoptimierung und vorausschauende Wartung
Risikoanalysen
Prozessautomatisierung
Die Möglichkeiten wachsen ständig.
Absolut – und es ist einfacher, als viele denken. Mit einer guten Anleitung kannst Du schnell die Grundlagen verstehen und erste eigene Modelle ausprobieren. In der FIDAcademy findest Du praxisnahe Kurse, die Dich Schritt für Schritt begleiten – vom Einsteiger bis zum Profi.



