
Che cos'è Deep Learning? Definizione - Funzionalità - Applicazione
Vi siete mai chiesti perché gli smartphone riconoscono i volti, perché le auto possono guidare da sole o perché i chatbot sembrano sempre più naturali? Dietro molte di queste piccole meraviglie tecniche c'è Deep Learning profondo, una sorta di "cervello" per i moderni sistemi di intelligenza artificiale. Deep Learning è solo un'area dell'intelligenza artificiale che può interpretare dati complessi e consentire processi di apprendimento automatizzati.
Deep Learning non è più un argomento del futuro. È ormai una componente centrale della ricerca e delle applicazioni dell'IA moderna. Influenza la vostra vita quotidiana, spesso senza che ve ne rendiate conto. In questo articolo vi mostrerò in modo comprensibile che cos'è davvero il deep learning, perché è così potente e come sta attualmente riorganizzando completamente il nostro mondo.
Questo articolo fornisce una chiara panoramica sul deep learning e aiuta a comprendere meglio le basi e le potenzialità di questa tecnologia.

Che cos'è Deep Learning? - Una definizione
Deep Learning si basa sulle reti neurali che rappresentano strutture di calcolo complesse e sono costituite da molti strati collegati in serie. Ciascuno dei numerosi strati (noti come strati nascosti) elabora le informazioni provenienti dallo strato precedente. In questo processo gerarchico, caratteristiche sempre più astratte (caratteristiche) vengono automaticamente e successivamente estratte e riconosciute dai dati in ogni fase. La funzionalità dell'Deep Learning si basa sull'estrazione automatica di caratteristiche gerarchiche e sul successivo riconoscimento di modelli in grandi insiemi di dati, al fine di ricavare in modo indipendente decisioni o previsioni.
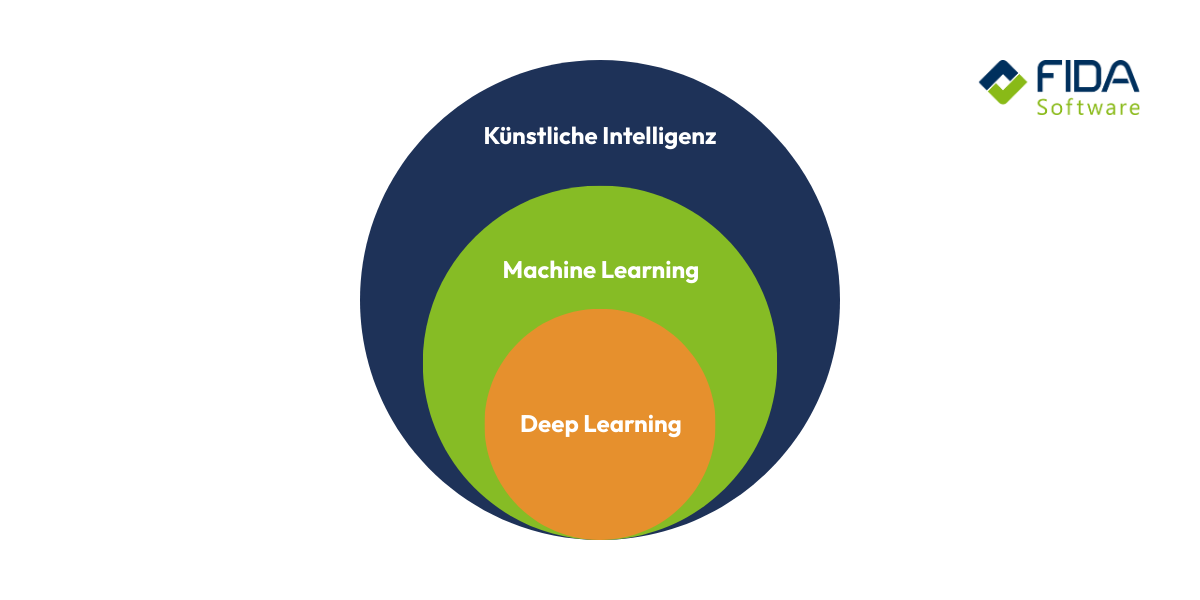
Qual è la differenza tra deep learning e machine learning?
Machine learning (ML) è il termine che racchiude tutti i metodi di intelligenza artificiale che consentono a un sistema di imparare dai dati e di fare previsioni o prendere decisioni senza una programmazione esplicita. Deep Learning (DL) è una sottocategoria dell'apprendimento automatico. La differenza principale risiede nell'architettura dei modelli utilizzati: ML utilizza modelli con architetture più semplici e piatte, mentre DL utilizza reti neurali profonde costituite da un gran numero di strati (strati nascosti).
Il modo in cui un modello apprende è definito dai cosiddetti paradigmi di apprendimento. Questi paradigmi sono indipendenti dal fatto che si tratti di un modello ML classico o di un modello DL.
I paradigmi di apprendimento più importanti sono
Apprendimento supervisionato: Il modello viene addestrato con dati ai quali è già associata la soluzione corretta (etichetta). L'obiettivo è imparare le relazioni tra i dati di input e le etichette. (Esempio: rilevamento di spam, classificazione di immagini).
Apprendimento non supervisionato: Il modello riceve dati senza etichette o obiettivi predefiniti. Deve riconoscere in modo indipendente schemi, strutture o somiglianze nei dati. (Esempio: segmentazione dei clienti, raggruppamento di documenti).
Apprendimento per rinforzo: Il modello impara agendo in un ambiente e ricevendo un feedback per le sue decisioni attraverso premi o punizioni. (Esempio: guida autonoma, giochi come il Go o gli scacchi).
Sebbene i compiti che possono essere risolti con l'apprendimento automatico classico possano, in linea di principio, essere risolti anche con Deep Learning, l'uso di reti neurali potenti può essere eccessivo in casi semplici ("sparare ai passeri con i cannoni").
Per compiti molto complessi e per quantità di dati estremamente elevate, i modelli di deep learning tendono a scalare meglio rispetto ai modelli di machine learning classici, poiché la loro architettura è progettata per estrarre automaticamente caratteristiche più profonde dalla ricchezza dei dati.
Per quanto riguarda lo sviluppo delle prestazioni, va notato che: Sebbene sia i modelli di machine learning che quelli di deep learning raggiungano alla fine un plateau di prestazioni, la maggiore capacità delle reti DL consente loro di raggiungere questo punto più tardi rispetto ai modelli ML meno profondi e di beneficiare quindi di un maggior numero di dati. Tuttavia, è importante sottolineare che un numero maggiore di dati non garantisce sempre automaticamente prestazioni migliori. Una qualità insufficiente dei dati o una configurazione inadeguata del modello possono influire negativamente sulle prestazioni di un modello - sia esso di ML o di DL - o addirittura portare a una degenerazione.
Deep Learning e l'apprendimento automatico si differenziano quindi principalmente per la loro architettura e per la capacità associata di estrarre caratteristiche automatizzate e gerarchiche da dati non strutturati o molto complessi, non per i paradigmi di apprendimento di base.

Come funziona Deep Learning?
Per capire come funziona il deep learning, si può pensare alle reti neurali artificiali come a una versione digitale semplificata del nostro cervello. La potenza del deep learning si basa sulla stretta collaborazione di molte reti complesse che lavorano insieme per elaborare grandi quantità di dati e riconoscere i modelli. Ogni rete è composta da molti piccoli "neuroni" che elaborano i dati. Questi neuroni utilizzano i valori di input, i pesi e i cosiddetti valori di bias per riconoscere gli schemi, come se stessero imparando passo dopo passo cosa c'è nei dati.
Una rete neurale profonda è costituita da diversi strati collegati in serie. Ogni strato si basa sui risultati del precedente e rende il riconoscimento sempre più preciso. Quando i dati scorrono in avanti attraverso la rete, dallo strato di ingresso a quello di uscita, si parla di propagazione in avanti. Lo strato di uscita è l'ultimo strato della rete neurale e fornisce il risultato finale del modello.
Tuttavia, affinché la rete diventi davvero "intelligente", ha bisogno di essere addestrata. È qui che entra in gioco la retropropagazione. Il modello verifica i propri errori, calcola quanto ha sbagliato e regola i pesi negli strati passo dopo passo. Per ottimizzare i pesi vengono utilizzati algoritmi speciali che consentono di cogliere anche correlazioni complesse in grandi serie di dati. Questo processo continua fino a quando le previsioni diventano sempre più accurate. Si può pensare a un processo di apprendimento: provare, sbagliare, adattarsi e ricominciare.
Una digressione: tutto questo è estremamente intensivo dal punto di vista computazionale. Deep Learning richiede un'enorme potenza, motivo per cui vengono spesso utilizzate le GPU. Questi processori specializzati sono in grado di elaborare enormi quantità di dati in parallelo. Anche i servizi cloud contribuiscono a fornire la potenza di calcolo necessaria, soprattutto quando molte GPU devono lavorare insieme. Dal punto di vista del software, per sviluppare e addestrare i modelli di deep learning si utilizzano soprattutto framework come JAX, PyTorch o TensorFlow.
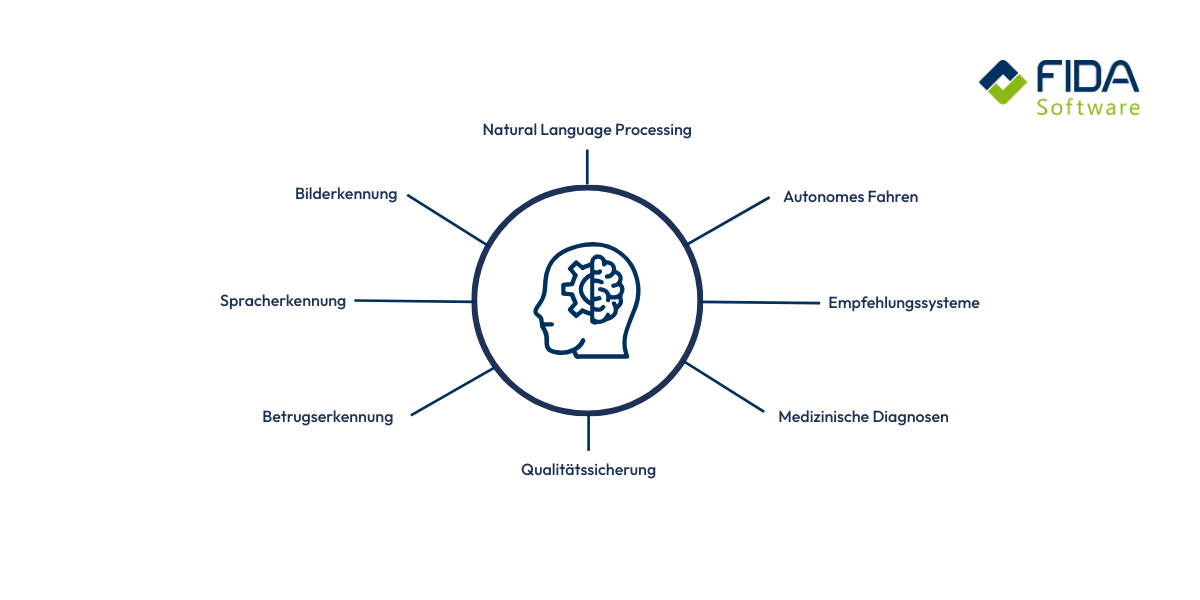
A cosa serve Deep Learning?
Deep Learning è presente in innumerevoli settori, spesso senza che ve ne rendiate conto. Quando il vostro smartphone riconosce i volti, i servizi di streaming vi danno consigli su misura o le app di navigazione prevedono il traffico, di solito c'è dietro il deep learning. In medicina, la tecnologia aiuta a riconoscere più rapidamente le malattie sulle immagini. Nell'industria, garantisce che le macchine rilevino automaticamente gli errori o che i processi produttivi funzionino in modo più efficiente. Le auto a guida autonoma si affidano al deep learning per comprendere l'ambiente circostante. In breve, ovunque sia necessario analizzare grandi quantità di dati e riconoscere modelli complessi, Deep Learning è lo strumento che rende tutto ciò possibile.

1. riconoscimento di immagini e oggetti
Deep Learning è in grado di analizzare le immagini e di riconoscere gli oggetti in esse contenuti, con precisione e in frazioni di secondo. Forse lo conoscete già dal vostro smartphone, dove la fotocamera riconosce automaticamente i volti o identifica soggetti come il cielo, le piante o gli animali. In medicina, la stessa tecnologia viene utilizzata per individuare tumori o anomalie nelle immagini di risonanza magnetica o a raggi X, spesso in modo più rapido e affidabile dell'occhio umano.

2. elaborazione del linguaggio e del testo
Che si tratti di app di traduzione, chatbot o assistenti virtuali, il deep learning garantisce che le macchine comprendano il linguaggio e generino risposte in modo indipendente. In particolare, i moderni modelli di trasformazione (la base dei grandi modelli linguistici/LLM come ChatGPT) hanno fatto un passo avanti in questo settore. Quando chiedete al vostro smartphone di ricordarvi qualcosa o quando fate tradurre automaticamente dei testi, un modello di deep learning lavora in background per convertire il linguaggio in significato.

3. raccomandazioni personalizzate
Servizi di streaming come Netflix o Spotify utilizzano il deep learning per suggerire film, serie o canzoni che soddisfano i vostri gusti. Anche i negozi online utilizzano questa tecnologia per mostrarvi i prodotti che trovate effettivamente interessanti. Il sistema impara dal comportamento dell'utente - ciò che guarda, clicca o acquista - e migliora costantemente i suoi suggerimenti.

4. guida autonoma
Affinché un'auto possa guidare in modo autonomo, deve "capire" con precisione l'ambiente circostante. Telecamere, sensori e radar forniscono enormi quantità di dati: il deep learning li analizza in tempo reale e riconosce pedoni, altri veicoli, segnali stradali e ostacoli. Solo grazie a questa rapida elaborazione un veicolo può reagire in modo sicuro e affidabile.

5. garanzia di qualità nell'industria
Le macchine delle fabbriche moderne utilizzano il deep learning per individuare tempestivamente i difetti dei prodotti o per ottimizzare i processi. Ad esempio, una telecamera può controllare ogni componente e segnalare immediatamente le irregolarità. Ciò consente di risparmiare sui costi, aumentare la qualità e rendere i processi più efficienti.

6. mondo finanziario e rilevamento delle frodi
Le banche e i fornitori di servizi di pagamento utilizzano il deep learning per rilevare transazioni insolite.
Il sistema riconosce gli schemi di comportamento e dà l'allarme se qualcosa non quadra.
In questo modo si evita che i pagamenti fraudolenti possano sfuggire.

Quali tipi di modelli di deep learning esistono?
L'architettura di una rete neurale determina il tipo di dati che può elaborare meglio. I modelli più importanti nel deep learning sono
1. reti neurali convoluzionali (CNN)
Le CNN sono l'architettura standard per l'elaborazione delle immagini. Utilizzano filtri speciali(strati convoluzionali) per estrarre caratteristiche gerarchiche come bordi, forme e texture dai dati dei pixel.
Vantaggi: Eccellenti per il riconoscimento di immagini e modelli.
Svantaggi: Meno adatte a dati sequenziali (testo, serie temporali).
2. reti neurali ricorrenti (RNN)
Le RNN sono progettate appositamente per l'elaborazione di dati sequenziali (serie temporali, parlato), in quanto possono memorizzare le informazioni dei passaggi precedenti. Le varianti moderne, come le LSTM (Long Short-Term Memory), risolvono i problemi delle RNN precedenti.
Vantaggi: Ottime per le sequenze, previsioni di serie temporali.
Svantaggi: Addestramento lento, problemi con dipendenze molto lunghe.
3. autoencoder e autoencoder variazionali (VAE)
Gli autoencoder sono costituiti da un codificatore (che comprime i dati) e da un decodificatore (che li ricostruisce). Sono utilizzati principalmente per la riduzione delle dimensioni e il rilevamento di anomalie, imparando a rappresentare i dati "normali" nel miglior modo possibile.
Vantaggi: Efficace compressione dei dati, buona per la pulizia del rumore e il rilevamento di anomalie.
Svantaggi: La qualità della ricostruzione dipende fortemente dalla velocità di compressione.
4. reti generative avversarie (GAN)
Le GAN sono costituite da due reti - un generatore e un discriminatore - che si allenano l'una contro l'altra in una competizione. Il generatore produce nuovi dati realistici (ad esempio, immagini), mentre il discriminatore cerca di riconoscere i dati falsi.
Vantaggi: molto potente e perfetto per compiti generativi.
Svantaggi: L'addestramento è impegnativo e instabile, richiede molti dati.
5. modelli di diffusione
I modelli di diffusione generano immagini rimuovendo gradualmente il rumore - un processo che produce risultati molto stabili e di alta qualità. Molti generatori di immagini moderni utilizzano questo principio.
Vantaggi: qualità dell'immagine molto elevata, formazione più stabile rispetto alle GAN.
Svantaggi: L'addestramento può essere estremamente intensivo dal punto di vista computazionale; i modelli devono essere messi a punto in modo molto preciso.
6. modelli a trasformatori
I trasformatori hanno caratterizzato l'era moderna dell'IA. Elaborano il testo in parallelo, anziché parola per parola, e comprendono così le relazioni complesse del linguaggio. Oggi questa architettura è alla base di chatbot, traduttori, classificazione di testi, riassunti e di modelli linguistici di grandi dimensioni come ChatGPT.
Vantaggi: Veloce, altamente scalabile, eccellente nel gestire il linguaggio e i contesti lunghi.
Svantaggi: Costi di formazione enormi, grande necessità di dati di alta qualità.

Capire Deep Learning: il vostro ingresso nel futuro dell'IA
Deep Learning è oggi una delle aree più interessanti dell'intelligenza artificiale. Che si tratti di riconoscimento di immagini, elaborazione del parlato o sistemi autonomi, questa tecnologia mostra i suoi punti di forza quando è necessario elaborare grandi quantità di dati e riconoscere modelli complessi. Abbiamo visto come funziona il deep learning, quali tipi di modelli esistono e come si differenzia dal machine learning classico. Soprattutto, però, è chiaro che più alta è la qualità dei dati e la capacità di una rete neurale, più precisa e potente può diventare.
Se volete approfondire il mondo dell'IA, la FIDAcademy è il supporto giusto per voi. Vi attendono corsi di formazione pratica e di approfondimento su temi quali l'intelligenza artificiale, le reti neurali e i moderni metodi di apprendimento automatico. In questo modo potrete ampliare le vostre conoscenze in modo mirato e comprendere le tecnologie che stanno plasmando il nostro futuro digitale.
FAQ - Domande frequenti sull'apprendimento profondo
L'apprendimento profondo è una branca dell'intelligenza artificiale che si basa su reti neurali artificiali con molti strati. Queste complesse strutture di calcolo sono in grado di riconoscere le caratteristiche in modo gerarchico in grandi quantità di dati e di apprendere in modo indipendente.
L'apprendimento profondo è una sottocategoria dell'apprendimento automatico e si differenzia principalmente in termini di architettura (reti profonde). Nell'apprendimento automatico classico, le caratteristiche devono spesso essere definite manualmente, mentre i modelli di apprendimento profondo apprendono le caratteristiche rilevanti direttamente dai dati grezzi. I paradigmi di apprendimento di base (come l'apprendimento supervisionato) sono indipendenti da ML o DL.
Le reti neurali elaborano i dati strato per strato. Il modello rileva gli errori durante l'addestramento e regola i suoi pesi utilizzando la retropropagazione. In questo modo, migliora le sue previsioni passo dopo passo. Questo richiede spesso un hardware speciale, come le GPU.
L'apprendimento profondo viene utilizzato, tra l'altro, per
Riconoscimento di immagini e oggetti
Elaborazione del parlato e chatbot (in particolare i modelli di trasformazione)
Sistemi di raccomandazione
Guida autonoma
Rilevamento di anomalie e frodi
Controllo di qualità nell'industria
I tipi di modelli più importanti includono
Reti neurali convoluzionali (CNN)
Reti neurali ricorrenti (RNN)
Autoencoder
Reti avversarie generative (GAN)
Modelli di diffusione
Modelli di trasformazione
I modelli di apprendimento profondo spesso richiedono molti dati di alta qualità, molta potenza di calcolo e possono essere difficili da interpretare. Se la qualità o la varietà dei dati è insufficiente, vi è anche il rischio di degenerazione o di overfitting.
No. Per gli insiemi di dati più piccoli o strutturati, l'apprendimento automatico classico può essere più efficiente e più facile da gestire. L'apprendimento profondo è particolarmente utile per i dati non strutturati come le immagini, il parlato o il testo.
I framework più diffusi sono TensorFlow, PyTorch e JAX. Questi framework semplificano la creazione, l'addestramento e la distribuzione delle reti neurali.



