
What is deep learning? Definition - Functionality - Application
Have you ever wondered why smartphones now recognize faces, why cars can drive themselves or why chatbots seem more and more natural? Behind many of these small technical wonders lies deep learning - a kind of "brain" for modern AI systems. Deep learning is just one area of artificial intelligence that can interpret complex data and enable automated learning processes.
Deep learning is no longer a topic for the future. It is now a central component of modern AI research and application. It influences your everyday life - often without you even realizing it. In this article, I will show you in an understandable way what deep learning really is, why it is so powerful and how it is currently completely reorganizing our world.
This article provides you with an understandable overview of deep learning and helps you to better understand the basics and potential of this technology.

What is deep learning? - A definition
Deep learning is based on neural networks that represent complex computing structures and consist of many layers connected in series. Each of the many layers (known as hidden layers) processes the information from the previous layer. In this hierarchical process, increasingly abstract characteristics (features) are automatically and successively extracted and recognized from the data at each stage. The functionality of deep learning is based on the automated extraction of hierarchical features and subsequent pattern recognition in large data sets in order to independently derive decisions or predictions.
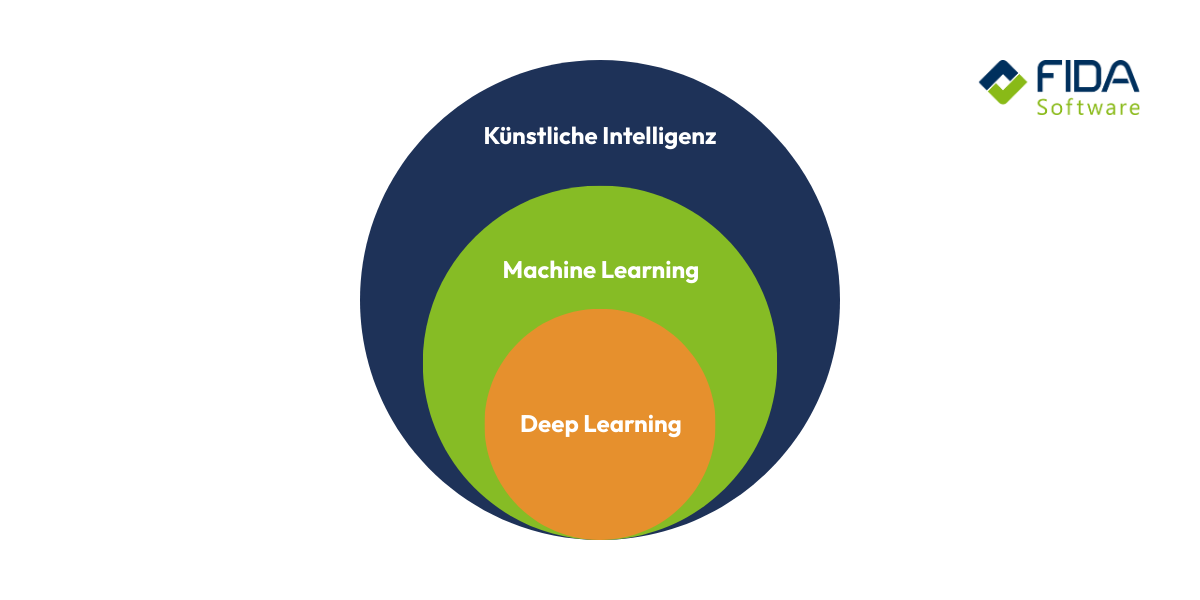
What is the difference between deep learning and machine learning?
Machine learning (ML) is the umbrella term for all artificial intelligence methods that enable a system to learn from data and make predictions or decisions without explicit programming. Deep learning (DL) is a subcategory of machine learning. The main difference lies in the architecture of the models used: ML uses models with simpler, flatter architectures, while DL uses deep neural networks consisting of a large number of layers (hidden layers).
The way in which a model learns is defined by so-called learning paradigms. These paradigms are independent of whether it is a classic ML model or a DL model.
The most important learning paradigms include
Supervised Learning: The model is trained with data to which the correct solution (label) is already attached. The aim is to learn the relationships between the input data and the labels. (Example: spam detection, classification of images)
Unsupervised learning: The model receives data without predefined labels or targets. It should independently recognize patterns, structures or similarities in the data. (Example: customer segmentation, clustering of documents)
Reinforcement learning: The model learns by acting in an environment and receiving feedback for its decisions through rewards or punishments. (Example: autonomous driving, games such as Go or chess)
Although tasks that can be solved with classic machine learning can in principle also be solved with deep learning, the use of powerful neural networks can be excessive in simple cases ("shooting sparrows with cannons").
For very complex tasks and extremely large amounts of data, deep learning models tend to scale better than classic machine learning models, as their architecture is designed to automatically extract deeper features from the wealth of data.
With regard to performance development, it should be noted: While both machine learning and deep learning models eventually reach a performance plateau, the higher capacity of DL networks allows them to tend to reach this point later compared to shallower ML models and thus benefit from more data. However, it is important to emphasize that more data does not always automatically guarantee better performance. Insufficient data quality or an unsuitable model configuration can negatively impact the performance of a model - whether ML or DL - or even lead to degeneration.
Deep learning and machine learning therefore differ primarily in their architecture and the associated ability to extract automated, hierarchical features from unstructured or very complex data, not in the basic learning paradigms.

How does deep learning work?
To understand how deep learning works, you can think of artificial neural networks as a simplified digital version of our brain. The power of deep learning is based on the close collaboration of many complex networks that work together to process large amounts of data and recognize patterns. Each network consists of many small "neurons" that process data. These neurons use input values, weights and so-called bias values to recognize patterns - as if they were learning step by step what is in the data.
A deep neural network consists of several layers connected in series. Each layer builds on the results of the previous one and makes the recognition more and more accurate. When data flows forward through this network - from the input layer to the output - this is known as forward propagation. The output layer is the last layer of the neural network and provides the final result of the model.
However, for the network to become really "smart", it needs training. This is where backpropagation comes into play. The model checks its own errors, calculates how much it was wrong and adjusts the weights in the layers step by step. Special algorithms are used to optimize the weights, which make it possible to capture even complex correlations in large data sets. This process continues until the predictions become more and more accurate. You can think of it as a learning process: try it out, make mistakes, adapt - and start all over again.
Digression: All of this is extremely computationally intensive. Deep learning requires enormous power, which is why GPUs are often used. These special processors are able to process huge amounts of data in parallel. Cloud services also help to provide the necessary computing power - especially when many GPUs need to work together. On the software side, frameworks such as JAX, PyTorch or TensorFlow are mainly used today to develop and train deep learning models.
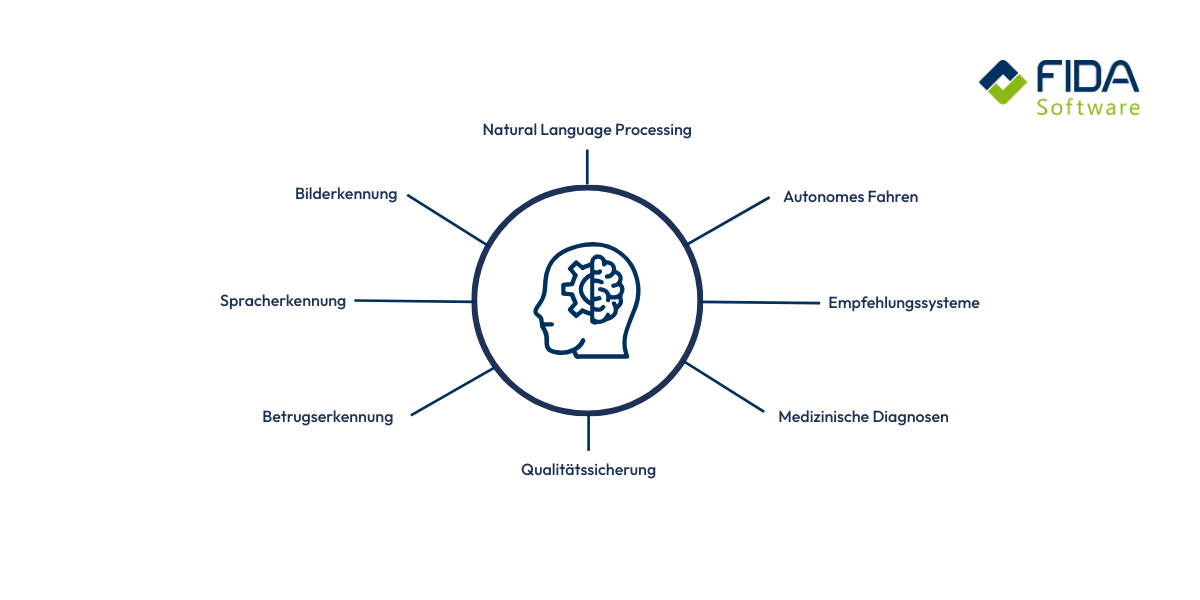
What is deep learning used for?
Deep learning can be found in countless areas today - often without you even realizing it. When your smartphone recognizes faces, streaming services give you precise recommendations or navigation apps predict traffic, deep learning is usually behind it. In medicine, the technology helps to detect diseases on images more quickly. In industry, it ensures that machines detect errors automatically or that production processes run more efficiently. Self-driving cars rely on deep learning to understand their surroundings. In short, wherever large amounts of data need to be evaluated and complex patterns recognized, deep learning is the tool that makes it all possible.

1. image and object recognition
Deep learning can analyze images and recognize objects in them - precisely and in fractions of a second. You may be familiar with this from your smartphone, when the camera automatically recognizes faces or identifies subjects such as the sky, plants or animals. In medicine, the same technology is used to find tumors or abnormalities on MRI or X-ray images - often faster and more reliably than the human eye.

2. language and text processing
Whether translation apps, chatbots or virtual assistants - deep learning ensures that machines understand language and generate answers independently. Modern transformer models in particular (the basis of large language models/LLMs such as ChatGPT) have achieved a breakthrough in this area. When you ask your smartphone to remind you of something or when you have texts translated automatically, a deep learning model is working in the background to convert language into meaning.

3. personalized recommendations
Streaming services such as Netflix or Spotify use deep learning to suggest films, series or songs that suit your tastes. Online stores also use the technology to show you products that you actually find interesting. The system learns from your behavior - what you look at, click on or buy - and constantly improves its suggestions.

4. autonomous driving
For a car to drive autonomously, it must "understand" its surroundings precisely. Cameras, sensors and radar provide huge amounts of data - deep learning analyzes them in real time and recognizes pedestrians, other vehicles, traffic signs or obstacles. Only through this rapid processing can a vehicle react safely and reliably.

5. quality assurance in industry
Machines in modern factories use deep learning to detect defects in products at an early stage or to optimize processes. For example, a camera can check every component and report irregularities immediately. This saves costs, increases quality and makes processes more efficient.

6. financial world and fraud detection
Banks and payment providers use deep learning to detect unusual transactions.
The system recognizes patterns in behavior - and sounds the alarm if something doesn't fit.
This prevents fraudulent payments from slipping through.

What types of deep learning models are there?
The architecture of a neural network determines what type of data it can process best. The most important models in deep learning are
1. convolutional neural networks (CNNs)
CNNs are the standard architecture for image processing. They use special filters(convolutional layers) to extract hierarchical features such as edges, shapes and textures from pixel data.
Advantages: Excellent for image and pattern recognition.
Disadvantages: Less suitable for sequential data (text, time series).
2. recurrent neural networks (RNNs)
RNNs are specially designed for processing sequential data (time series, speech) as they can store information from previous steps. Modern variants such as LSTMs (Long Short-Term Memory) solve the problems of earlier RNNs.
Advantages: Good for sequences, predictions of time series.
Disadvantages: Slow training, problems with very long dependencies.
3. autoencoders & variational autoencoders (VAEs)
Autoencoders consist of an encoder (which compresses data) and a decoder (which reconstructs it). They are primarily used for dimension reduction and anomaly detection by learning to represent the "normal" data as well as possible.
Advantages: Effective data compression, good for cleaning up noise and anomaly detection.
Disadvantages: The quality of the reconstruction depends heavily on the compression rate.
4. generative adversarial networks (GANs)
GANs consist of two networks - a generator and a discriminator - that train against each other in a competition. The generator produces new, realistic data (e.g. images), while the discriminator tries to recognize the fake data.
Advantages: Very powerful and perfect for generative tasks.
Disadvantages: Training is demanding and unstable, requires a lot of data.
5. diffusion models
Diffusion models generate images by gradually removing noise - a process that produces very stable and high-quality results. Many modern image generators use this principle.
Advantages: Very high image quality, more stable training than GANs.
Disadvantages: Training can be extremely computationally intensive; models need a lot of fine-tuning.
6. transformer models
Transformers have shaped the modern age of AI. They process text in parallel instead of word by word and thus understand complex relationships in language. Today, this architecture is behind chatbots, translators, text classification, summaries - and behind large language models such as ChatGPT.
Advantages: Fast, highly scalable, excellent at handling language and long contexts.
Disadvantages: Huge training costs, great need for high-quality data.

Understanding deep learning - your entry into the future of AI
Deep learning is one of the most exciting areas of artificial intelligence today. Whether image recognition, speech processing or autonomous systems - this technology shows its strengths wherever large amounts of data need to be processed and complex patterns recognized. You have seen how deep learning works, what types of models there are and how it differs from traditional machine learning. Above all, however, it becomes clear that the higher the data quality and capacity of a neural network, the more precise and powerful it can become.
If you want to delve deeper into the world of AI, the FIDAcademy is just the right support for you. Practical training and further education on topics such as artificial intelligence, neural networks and modern machine learning methods await you there. This will allow you to expand your knowledge in a targeted manner and understand the technologies that are shaping our digital future.
FAQ - Frequently asked questions about deep learning
Deep learning is a branch of artificial intelligence that is based on artificial neural networks with many layers. These complex computing structures can recognize features hierarchically in large amounts of data and learn independently.
Deep learning is a subcategory of machine learning and differs primarily in its architecture (deep networks). In classic machine learning, features often have to be defined manually, whereas deep learning models learn relevant features directly from the raw data. The basic learning paradigms (such as supervised learning) are independent of ML or DL.
Neural networks process data layer by layer. The model detects errors during training and adjusts its weights using backpropagation. In this way, it improves its predictions step by step. This often requires special hardware such as GPUs.
Deep learning is used, among other things, for
Image and object recognition
Speech processing and chatbots (especially transformer models)
recommendation systems
Autonomous driving
Anomaly and fraud detection
Quality control in the industry
The most important model types include
Convolutional Neural Networks (CNNs)
Recurrent Neural Networks (RNNs)
Autoencoders
Generative Adversarial Networks (GANs)
Diffusion models
Transformer models
Deep learning models often require a lot of high-quality data, a lot of computing power and can be difficult to interpret. There is also a risk of degeneration or overfitting if the quality or variety of data is insufficient.
No. For smaller or structured data sets, classic machine learning can be more efficient and easier to handle. Deep learning is particularly worthwhile for unstructured data such as images, speech or text.
Popular frameworks include TensorFlow, PyTorch and JAX. They make it easier to create, train and deploy neural networks.



